Jaki cel przyświeca nam w tym kursie? Chcesz pobrać dane ze stron internetowych i umieścić je bazie danych. Jak pewnie wiesz, lub się domyślasz, w bazie danych znajdują się tabele z danymi. W tej części spróbujemy właśnie tabele pobrać. Ćwiczenie zacznijmy na stronach Wikipedii. Wikipedia jest wdzięcznym źródłem danych, wszystko, co widać na stronie można pobrać bez żadnych trudności. Miej jednak w pamięci, że masowe pobieranie danych napisanym programem może znacząco obciążyć serwery i dostęp do nich może Ci zostać czasowo zablokowany.
Pamiętaj też, że nie każda strona zezwala na pobieranie danych, warto zapoznać się z informacją co można a czego nie można.
Wejdźmy na stronę Wikipedii o mieście Radom. Pierwsza tabela którą znalazłem dotyczy klimatu. Poprzednio podglądaliśmy źródło strony, ale jeśli zrobisz to ze stroną o Radomiu, zauważysz, że strona ta ma blisko 3 000 linijek kodu! Trudno będzie znaleźć interesującą nas tabelę. Na szczęście można zrobić to prościej. Kliknij w dowolnym miejscu tabeli prawym klawiszem myszy i z menu wybierz opcję Zbadaj element. W zależności od przeglądarki ta opcja może nazywać się po prostu Zbadaj.
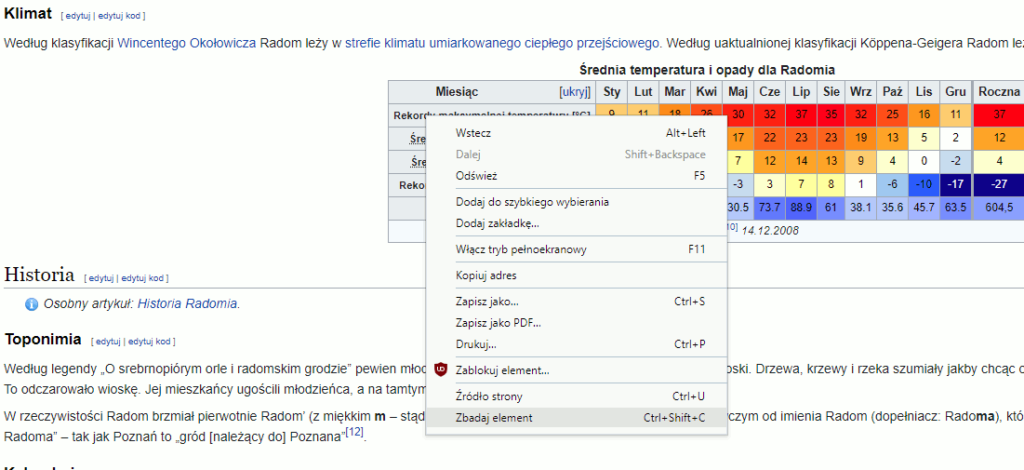
Po kliknięciu tej opcji, otworzy się dodatkowe okno w przeglądarce podobne do tego poniżej:
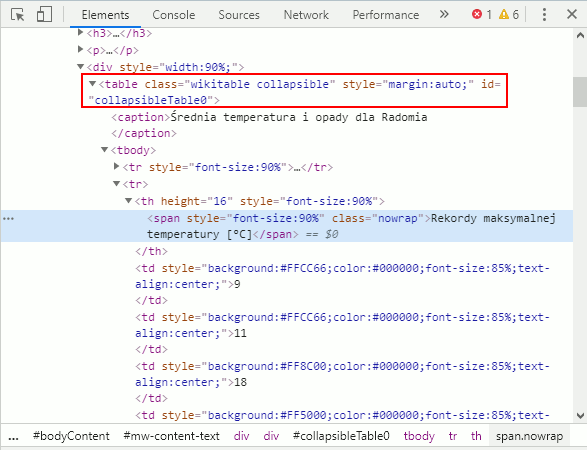
Jak widzisz tutaj całe źródło strony jest poukładane w przejrzysty, hierarchiczny sposób. W zależności na który element tabeli kliknąłeś, na niebiesko będzie podświetlony wybrany element tabeli. U mnie jest to wyróżniony tekst (tag <span>), który znajduje się w nagłówku tabeli (tag <th> linijkę wyżej), który znajduje się w linijce tabeli (tag <tr> linijkę wyżej), która znajduje się w „ciele” tabeli (tag <tbody> linijkę wyżej), które to w końcu znajduje się w tabeli (tag <table> wyżej). Widzisz, każdy tag, który jest częścią innego tagu (tabela składa się z wierszy, komórek i danych w komórkach) jest wcięty. Klikając małe, czarne strzałki możesz poszczególne elementy zwijać i rozwijać.
Spróbujmy napisać program, który wyświetli tą pierwszą tabele, powinno pójść całkiem łatwo.
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table")
print(tabela)
W 4 linijce definiujemy zmienną ze stroną Wikipedii o Radomiu. W 7 linijce szukasz pierwszej tabeli po tagu table, w 9 linijce drukujesz tabelę. Zobaczmy efekt:
==================== RESTART: F:/python38/Web scraping 05.py ===================
<table class="noprint disambig" id="Vorlage_Alternative" style="line-height:23px; padding-left: 3px; background-color: #f9f9f9; border-bottom: 1px solid #cccccc; font-size: 95%; margin-bottom: 1em">
<tbody><tr><td>
<a href="/wiki/Wikipedia:Strona_ujednoznaczniaj%C4%85ca" title="Inne znaczenia"><img alt="" data-file-height="183" data-file-width="230" decoding="async" height="20" src="//upload.wikimedia.org/wikipedia/commons/thumb/7/72/Disambig.svg/25px-Disambig.svg.png" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/7/72/Disambig.svg/38px-Disambig.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/7/72/Disambig.svg/50px-Disambig.svg.png 2x" width="25"/></a></td>
<td style="width: 100%;">Ten artykuł dotyczy miasta w województwie mazowieckim. Zobacz też: <a class="mw-disambig" href="/wiki/Radom_(ujednoznacznienie)" title="Radom (ujednoznacznienie)">inne znaczenia tej nazwy</a>.</td>
</tr></tbody></table>
>>> No… to na pewno nie jest nasza tabela! Spróbujmy być bardziej precyzyjni. Popatrz na inne informacje jakie masz o tabeli: table class=”wikitable collapsible” style=”margin:auto;” id=”collapsibleTable0″
Używając .find() możesz podać więcej niż jeden argument. Popatrz na przykład:
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
print(tabela)
W 7 linijce prócz argumentu "table" dodaliśmy drugi, class_="wikitable collapsible". Słowo class ma specjalne znaczenie w Pythonie, dlatego w funkcji .find() musimy go użyć z podkreślnikiem i to jest wyjątkowa sytuacja. Teraz funkcja .find() szuka tabel, których nazwa klasy jest równa wikitable collapsible. Zobaczmy efekt:
==================== RESTART: F:\python38\Web scraping 05.py ===================
<table class="wikitable collapsible" style="margin:auto;">
<caption>Średnia temperatura i opady dla Radomia
</caption>
<tbody><tr style="font-size:90%">
<th>Miesiąc
</th>
<th abbr="Styczeń">Sty
</th>
<th abbr="Luty">Lut
</th>
<th abbr="Marzec">Mar
</th>
<th abbr="Kwiecień">Kwi
</th>
<th abbr="Maj">Maj
</th>
<th abbr="Czerwiec">Cze
</th>
<th abbr="Lipiec">Lip
</th>
<th abbr="Sierpień">Sie
</th>
<th abbr="Wrzesień">Wrz
</th>
<th abbr="Październik">Paź
</th>
<th abbr="Listopad">Lis
</th>
<th abbr="Grudzień">Gru
</th>
<th style="border-left-width:medium">Roczna
</th></tr>
<tr>
<th height="16" style="font-size:90%"><span class="nowrap" style="font-size:90%">Rekordy maksymalnej temperatury [°C]</span>
</th>
<td style="background:#FFCC66;color:#000000;font-size:85%;text-align:center;">9
</td>
<td style="background:#FFCC66;color:#000000;font-size:85%;text-align:center;">11
</td>
<td style="background:#FF8C00;color:#000000;font-size:85%;text-align:center;">18
</td>
<td style="background:#FF5000;color:#000000;font-size:85%;text-align:center;">26
</td>
<td style="background:#FF2800;color:#000000;font-size:85%;text-align:center;">30
</td>
<td style="background:#FF2800;color:#000000;font-size:85%;text-align:center;">32
</td>
<td style="background:#FF0000;color:#000000;font-size:85%;text-align:center;">37
</td>
<td style="background:#FF1400;color:#000000;font-size:85%;text-align:center;">35
</td>
<td style="background:#FF2800;color:#000000;font-size:85%;text-align:center;">32
</td>
<td style="background:#FF5000;color:#000000;font-size:85%;text-align:center;">25
</td>
<td style="background:#FF9900;color:#000000;font-size:85%;text-align:center;">16
</td>
<td style="background:#FFCC66;color:#000000;font-size:85%;text-align:center;">11
</td>
<td style="background:#FF0000;color:#000000;font-size:85%;text-align:center; border-left-width:medium">37
</td></tr>
<tr>
<th height="16" style="font-size:90%"><span class="nowrap" style="font-size:90%"><abbr class="abbr" title="Średnie maksymalne temperatury w dzień">Średnie temperatury w dzień [°C]</abbr></span>
</th>
<td style="background:#C8DCF0;color:#000000;font-size:85%;text-align:center;">-1
</td>
<td style="background:#C8DCF0;color:#000000;font-size:85%;text-align:center;">-1
</td>
<td style="background:#FFFFCC;color:#000000;font-size:85%;text-align:center;">4
</td>
(...)
<td colspan="14" style="text-align:center;font-size:88%"><i>Źródło: Weatherbase<sup class="reference" id="cite_ref-Weatherbase_10-0"><a href="#cite_note-Weatherbase-10">[10]</a></sup> 14.12.2008</i>
</td></tr></tbody></table>
>>> Strasznie długa ta tabela, prawda? Użyjmy metody .get_text(), by pozbyć się wszystkich niepotrzebnych informacji.
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
print(tabela.get_text())
I efekt:
============================= RESTART: F:\python38\Web scraping 05.py =============================
Średnia temperatura i opady dla Radomia
Miesiąc
Sty
Lut
Mar
Kwi
Maj
Cze
Lip
Sie
Wrz
Paź
Lis
Gru
Roczna
Rekordy maksymalnej temperatury [°C]
9
11
18
26
30
32
37
35
32
25
16
11
37
(...)
Źródło: Weatherbase[10] 14.12.2008W naszej tabeli mamy jeszcze jeden identyfikator – id (table class=”wikitable collapsible” style=”margin:auto;” id=”collapsibleTable0″). Byłoby sensownie użyć id a nie class, intuicyjnie spodziewasz się, że na stronie może być kilka tabeli tej samej klasy, ale id powinno być unikatowe. Poprawmy program:
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", id="collapsibleTable0")
print(tabela)
Zobaczmy wynik:
============================= RESTART: F:\python38\Web scraping 05.py =============================
None
>>> Wynikiem jest wartość None, co znaczy, że Python nie znalazł takiej tabeli. Jak to możliwe? Otóż używając opcji Zbadaj element otrzymujesz trochę więcej informacji niż znajduje się w źródle strony, które odczytuje BeautifulSoup. Jeśli spojrzysz w źródło, strony dla naszej tabeli znajdziesz tam: <table class=”wikitable collapsible” style=”margin:auto;”>, żadnego id! Dobieraniem się do „niewidocznych” treści nie będziemy zajmować się w tym kursie.
Sposób w jaki wyświetliła nam się tabela nie jest dla nas użyteczny. Na pierwszy rzut oka nie wiadomo do końca co odpowiada jakim wartościom. Spróbujmy zapisać wartości tabeli w bardziej użytecznej formie, czyli listy. Zróbmy to krok po kroku.
Potrzebujesz na liście zapisać osobno wartość z każdego wiersza. To może najpierw napiszmy pętlę, która wyświetli nam każdy z wierszy? Wiemy, że znacznikiem wiersza jest tr. Napiszmy pętlę, która to wykorzysta:
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
for wiersz in tabela.findAll("tr"):
print(wiersz.get_text())
W 9 linijce zaczynamy pętlę, w której pod zmienną wiersz znajdą się wszystkie wiersze (tr). W 11 linicje te wiersze są drukowane. Zobaczmy efekt:
=============================================================== RESTART: F:\python38\Web scraping 05.py ===============================================================
Miesiąc
Sty
Lut
Mar
Kwi
Maj
Cze
Lip
Sie
Wrz
Paź
Lis
Gru
Roczna
Rekordy maksymalnej temperatury [°C]
9
11
18
26
30
32
37
35
32
25
16
11
37
(...)
Źródło: Weatherbase[10] 14.12.2008
>>> Niespecjalnie widać różnicę w porównaniu do poprzedniego programu. By poprawić czytelność użyjemy metody .replace().
Usuwanie znaków nowej linii
Działanie tej metody zobaczmy na prostym przykładzie. Przypomnijmy nasze działanie na nagłówkach z poprzedniej części:
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://inferiordatascience.com/przyklad.html"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
naglowki = html.findAll("h1")
for h1 in naglowki:
print(h1.get_text())
I zobaczmy efekt:
=================== RESTART: F:\python38\Web scraping 05.py ===================
This
Is The Very Last Page On The Internet
Please
turn off your computer!!!
Go
outside and play!!!
The
End.
>>> Być może już wtedy twoje poczucie estetyki zostało urażone tym, że każdy z nagłówków zajmował dwie linijki, z podziałem po pierwszym słowie. Jeśli zajrzysz w źródło strony, to zobaczysz, że dokładnie tak jest tam zapisany każdy z nagłówków, po pierwszym słowie pojawia się nowa linijka. Strona wyświetla się prawidłowo, bo przeglądarka ma w nosie ile tam jest nowych linijek. Póki nie ma znacznika HTML nowej linii (<br>), to traktuje się każdy tekst jako jedną linijkę. Innymi słowy HTML nie rozumie nowej linii i ją ignoruje. Inaczej ma się sprawa z tekstem wyciągniętym ze źródła strony. Na nasze nieszczęście Python już taki znak nowej linii rozumie i musimy się go pozbyć. Popatrz na taki prosty przykład:
tekst = """To jest tekst
z nową linijką. """
print(tekst)
print(tekst.replace("\n", ""))
W 1 linijce mamy zmienną tekst, pod którą podstawiamy tekst składający się z 2 linijek. Potrójny cudzysłów pozwala na użycie entera bez utraty ciągłości stringa (spróbuj zamienić potrójne cudzysłowy na pojedyncze i sprawdź jaki będzie efekt). W 4 linijce drukujemy tekst. W 5 linijce używamy metody .replace(), która działa podobnie jak znajdź i zamień w popularnych programach biurowych. Argumentami funkcji musi być informacja czego szukamy i na co zamieniamy. My szukamy znaku nowej linii "\n" i zamieniamy go na nic "", czyli usuwamy. Do znaczenia"\n" jeszcze wrócimy. Zobaczmy efekt działania programu:
=================== RESTART: F:/python38/prosty przyklad.py ===================
To jest tekst
z nową linijką.
To jest tekst z nową linijką. Zadziałało. Jeśli chcesz podać tekst w pojedynczych cudzysłowach, to musisz zrobić to tak:
tekst = "To jest tekst \nz nową linijką."
print(tekst)
print(tekst.replace("\n", ""))
Pewnie zastanawiasz się czemu \n ma jakieś moce. Backshlash (po polsku ukośnik wsteczny) ma specjalne znaczenie dla danych typu string. Backshlash to tak zwany escape character (po polsku znak modyfikacji lub ucieczki) i w połączeniu z literą ma nowe znaczenie. Kilka najpopularniejszych ukośników wraz z literami i ich znaczeniem:
- \n – nowa linia
- \t – tabulacja
- \’ – pojedynczy cudzysłów
- \” – podwójny cudzysłów
- \\ – backslash
Wykorzystajmy teraz .replace() na ostatniej stronie internetu:
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://inferiordatascience.com/przyklad.html"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
naglowki = html.findAll("h1")
for h1 in naglowki:
print(h1.get_text().replace("\n", ""))
W 10 linijce do metody .get_text() dodaliśmy jeszcze jedną, .replace("\n", ""). Zobaczmy efekt:
=================== RESTART: F:\python38\Web scraping 05.py ===================
This Is The Very Last Page On The Internet
Please turn off your computer!!!
Go outside and play!!!
The End.
>>>
Pełen sukces, irytującymi odstępami miedzy pierwszym a drugim słowem nie będziemy się zajmować. Przełóżmy ten sposób na tabelę Średnich temperatur i opadów Radomia:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
for wiersz in tabela.findAll("tr"):
print(wiersz.get_text().replace("\n", " "))
I zobaczmy efekt:
=================== RESTART: F:\python38\Web scraping 05.py ===================
Miesiąc Sty Lut Mar Kwi Maj Cze Lip Sie Wrz Paź Lis Gru Roczna
Rekordy maksymalnej temperatury [°C] 9 11 18 26 30 32 37 35 32 25 16 11 37
Średnie temperatury w dzień [°C] -1 -1 4 12 17 22 23 23 19 13 5 2 12
Średnie temperatury w nocy [°C] -5 -7 -3 2 7 12 14 13 9 4 0 -2 4
Rekordy minimalnej temperatury [°C] -25 -27 -17 -6 -3 3 7 8 1 -6 -10 -17 -27
Opady [mm] 58.4 43.2 33 33 30.5 73.7 88.9 61 38.1 35.6 45.7 63.5 604,5
Źródło: Weatherbase[10] 14.12.2008
>>> Teraz dużo przyjemniej się czyta, prawda? Można zadać pytanie „Zaraz, zaraz a skąd wiadomo, że tam były jakieś znaki nowej linii?”. Prawdę mówiąc nie robiłem jakiegoś głębokiego śledztwa, po prostu poprzedni print był diablo długi i sprawdziłem co stanie się po usunięciu „\n”, efekt jest zadowalający.
W następnej części efekt wydrukowania tabeli spróbujemy przekuć w plik, który odczyta nawet arkusz kalkulacyjny.
Zadanie domowe
Podążanie za instrukcjami, nawet jeśli je wszystkie wykonujesz samodzielnie, nie zrobi z ciebie programisty. Zadania domowe mogą wydawać się na początku trudne. Tu nie ma rozwiązania podanego na talerzu, użyj dowolnych źródeł, by znaleźć odpowiedź.
- Na stronie https://pl.wikipedia.org/wiki/Radom znajdziesz sporo zdjęć. Gdy zajrzysz do źródła strony, zauważysz, że parametr alt zawiera tekst opisujący zdjęcie. Wydrukuj treść wszystkich parametrów alt z tagu <img>.
- Na tej samej stronie jest spis treści. Wydrukuj go.