W tej części będziemy kontynuować przygotowanie tabel do zapisu. Jednym ze sposobów jest umieszczenie wartości tabeli w liście, a potem zapisanie listy do pliku. Zapisanie listy do pliku, jak wkrótce się okaże, jest fantastycznie łatwe.
Zróbmy to krok po kroku, byś widział i zrozumiał cały proces. Zacznijmy od wydrukowania wierszy z użyciem znanej Ci instrukcji iteracyjnej for:
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
for wiersz in tabela.findAll("tr"):
print(wiersz)
break
W 9 linijce szukamy wszystkich wierszy tabeli (znacznik HTML <tr>) .
W 10 linijce je drukujemy.
W 11 linijce używam polecenia break, które powoduje, że pętla zostanie wykonana tylko raz, nie mamy potrzeby drukować wszystkich wierszy, jesteśmy na etapie testowania pomysłów. Zobaczmy wynik:
==================== RESTART: F:\python38\Web scraping 06.py ===================
<tr style="font-size:90%">
<th>Miesiąc
</th>
<th abbr="Styczeń">Sty
</th>
<th abbr="Luty">Lut
</th>
<th abbr="Marzec">Mar
</th>
<th abbr="Kwiecień">Kwi
</th>
<th abbr="Maj">Maj
</th>
<th abbr="Czerwiec">Cze
</th>
<th abbr="Lipiec">Lip
</th>
<th abbr="Sierpień">Sie
</th>
<th abbr="Wrzesień">Wrz
</th>
<th abbr="Październik">Paź
</th>
<th abbr="Listopad">Lis
</th>
<th abbr="Grudzień">Gru
</th>
<th style="border-left-width:medium">Roczna
</th></tr>
>>> Całkiem fajnie, mamy tutaj komórki tabeli z pierwszego wiersza i każda ma znacznik HTML <th>, czyli taki specjalny typ komórki, komórkę-nagłówek. By dobrać się do komórek w wierszu, w pętli wyszukującej wiersze musimy umieścić kolejną pętlę, która znajdzie każdą z komórek. Napiszmy dalszą cześć programu:
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
for wiersz in tabela.findAll("tr"):
print(wiersz)
for komorka_naglowka in wiersz.findAll("th"):
print(komorka_naglowka)
break
Jak widzisz w 11 linijce zaczynamy drugą pętlę for, która szuka we wcześniej znalezionych wierszach komórek znacznika<th>.
W 12 linijce drukujesz zmienną komorka_naglowka, pod którą podstawiane są kolejne komórki nagłówka. Zauważ, że instrukcja drugiej pętli for jest zagłębiona jedną tabulację bardziej w prawo.
W 13 linijce używamy polecenia break. Jest ono zagłębione na poziomie pierwszej pętli for. Dlaczego? Ano chcemy żeby to „duża” pętla wykonała się jeden raz, a mała tyle razy, ile komórek w wierszu występuje. Zobaczmy efekt:
==================== RESTART: F:\python38\Web scraping 05.py ===================
<tr style="font-size:90%">
<th>Miesiąc
</th>
<th abbr="Styczeń">Sty
</th>
<th abbr="Luty">Lut
</th>
<th abbr="Marzec">Mar
</th>
<th abbr="Kwiecień">Kwi
</th>
<th abbr="Maj">Maj
</th>
<th abbr="Czerwiec">Cze
</th>
<th abbr="Lipiec">Lip
</th>
<th abbr="Sierpień">Sie
</th>
<th abbr="Wrzesień">Wrz
</th>
<th abbr="Październik">Paź
</th>
<th abbr="Listopad">Lis
</th>
<th abbr="Grudzień">Gru
</th>
<th style="border-left-width:medium">Roczna
</th></tr>
<th>Miesiąc
</th>
<th abbr="Styczeń">Sty
</th>
<th abbr="Luty">Lut
</th>
<th abbr="Marzec">Mar
</th>
<th abbr="Kwiecień">Kwi
</th>
<th abbr="Maj">Maj
</th>
<th abbr="Czerwiec">Cze
</th>
<th abbr="Lipiec">Lip
</th>
<th abbr="Sierpień">Sie
</th>
<th abbr="Wrzesień">Wrz
</th>
<th abbr="Październik">Paź
</th>
<th abbr="Listopad">Lis
</th>
<th abbr="Grudzień">Gru
</th>
<th style="border-left-width:medium">Roczna
</th>
Jakoś tak bez szału, masz omalże dwa takie same wyniki, różnią się tylko brakem, bądź obecnością tagu HTML <tr>. Żeby działanie obejrzeć dobitniej, usuń break. Oczyśćmy jeszcze komórki za pomocą .get_text() i .replace(), nie potrzebujemy też drukować wiersza.
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
for wiersz in tabela.findAll("tr"):
for komorka_naglowka in wiersz.findAll("th"):
print(komorka_naglowka.get_text().replace("\n", ''))
break
Efekt będzie taki:
==================== RESTART: F:\python38\Web scraping 06.py ===================
Miesiąc
Sty
Lut
Mar
Kwi
Maj
Cze
Lip
Sie
Wrz
Paź
Lis
Gru
Roczna
>>> Teraz treść każdej z komórek chcemy umieścić na liście. Dodawania elementów do listy jeszcze nie ćwiczyliśmy. To całkiem proste zadanie, posłużysz się metodą .append(). Popatrz na przykład napisany prosto w linii komend IDLE:
>>> lista = []
>>> print(lista)
[]
>>> lista.append("Miesiąc")
>>> print(lista)
['Miesiąc']
>>> lista.append("Sty")
>>> print(lista)
['Miesiąc', 'Sty']W powyższym przykładzie najpierw pod zmienną lista podstawiamy pustą listę lista=[] i drukujemy ją, by pokazać jak bardzo jest pusta. Jak widzisz, dane listy będą znajdować się miedzy nawiasami kwadratowymi. Następnie na zmiennej lista używamy metody .append(), której argumentem jest string Miesiąc. Drukujemy znów zmienną lista i teraz na niej znajduje się dodany string. Następnie do zmiennej lista dodajemy metodą .append() kolejny string. Drukujemy zmienną lista trzeci raz i teraz ma ona dwa elementy, string Sty pojawił się po stringu Miesiąc.
Skoro już wiesz jak działa ta metoda, to pewnie widzisz jak łatwo można ją dodać do naszego programu.
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
for wiersz in tabela.findAll("tr"):
komorki_wiersza = []
for komorka_naglowka in wiersz.findAll("th"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
print(komorki_wiersza)
break
W 10 linijce definiujemy pustą listę pod zmienną komorki_wiersza.
W 12 linijce, w pętli for, zamiast drukować znalezione wartości komórki, dodajemy je do listy komorki_wiersza. W 13 linijce drukujemy efekt każdego przejścia pętli. Zobaczmy co się wydarzyło:
==================== RESTART: F:\python38\Web scraping 06.py ===================
['Miesiąc']
['Miesiąc', 'Sty']
['Miesiąc', 'Sty', 'Lut']
['Miesiąc', 'Sty', 'Lut', 'Mar']
['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi']
['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi', 'Maj']
['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi', 'Maj', 'Cze']
['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi', 'Maj', 'Cze', 'Lip']
['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi', 'Maj', 'Cze', 'Lip', 'Sie']
['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi', 'Maj', 'Cze', 'Lip', 'Sie', 'Wrz']
['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi', 'Maj', 'Cze', 'Lip', 'Sie', 'Wrz', 'Paź']
['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi', 'Maj', 'Cze', 'Lip', 'Sie', 'Wrz', 'Paź', 'Lis']
['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi', 'Maj', 'Cze', 'Lip', 'Sie', 'Wrz', 'Paź', 'Lis', 'Gru']
['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi', 'Maj', 'Cze', 'Lip', 'Sie', 'Wrz', 'Paź', 'Lis', 'Gru', 'Roczna']
>>> Dokładnie widać, jak nasza lista robi się coraz dłuższa o kolejne komórki pierwszego wiersza. Zauważ, że pustą listę musiałeś zadeklarować przed pętlą, jeśli znalazła by się w pętli, to za każdym razem resetowała by się do pustej listy. Możemy to nawet sprawdzić teraz:
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
for wiersz in tabela.findAll("tr"):
for komorka_naglowka in wiersz.findAll("th"):
komorki_wiersza = []
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
print(komorki_wiersza)
break
Efekt:
==================== RESTART: F:\python38\Web scraping 06.py ===================
['Miesiąc']
['Sty']
['Lut']
['Mar']
['Kwi']
['Maj']
['Cze']
['Lip']
['Sie']
['Wrz']
['Paź']
['Lis']
['Gru']
['Roczna']
>>> Poprawmy jeszcze trochę program, niech lista komórek wiesza drukuje się tylko raz, poza drugą pętlą:
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
for wiersz in tabela.findAll("tr"):
komorki_wiersza = []
for komorka_naglowka in wiersz.findAll("th"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
print(komorki_wiersza)
break
I zobaczmy efekt:
==================== RESTART: F:\python38\Web scraping 05.py ===================
['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi', 'Maj', 'Cze', 'Lip', 'Sie', 'Wrz', 'Paź', 'Lis', 'Gru', 'Roczna']
>>> Wygląda na to, że jesteśmy gotowi na usunięcie break i wydrukowanie list wartości dla każdego wiersza tabeli. Do dzieła! Tak będzie wyglądał kod programu:
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
for wiersz in tabela.findAll("tr"):
komorki_wiersza = []
for komorka_naglowka in wiersz.findAll("th"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
print(komorki_wiersza)
A tak efekt:
==================== RESTART: F:\python38\Web scraping 05.py ===================
['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi', 'Maj', 'Cze', 'Lip', 'Sie', 'Wrz', 'Paź', 'Lis', 'Gru', 'Roczna']
['Rekordy maksymalnej temperatury [°C]']
['Średnie temperatury w dzień [°C]']
['Średnie temperatury w nocy [°C]']
['Rekordy minimalnej temperatury [°C]']
['Opady [mm] ']
[]
>>> No i kurka, źle! Program co prawda zrobił dokładnie co napisałem by zrobił, poszukał tagów <th> i je umieścił w liście. Ale zupełnie zapomniałem, że wartości temperatur i opadów są w tagach <td>. Dodajmy trzecia pętlę. Chcemy, żeby wartości zapisane między tagami <td>, dodawały się do istniejących list z wartościami ze znaczników <th>, dlatego pętla będzie na tej samej „głębokości” co „pętla <th>”. Napisz potrzebny kod i sprawdź jak działa, może jest podobny do tego poniżej:
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
for wiersz in tabela.findAll("tr"):
komorki_wiersza = []
for komorka_naglowka in wiersz.findAll("th"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
for komorka_naglowka in wiersz.findAll("td"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
print(komorki_wiersza)
W linijkach 13-14 mamy pętlę, która rożni się od poprzedniej jedynie innym znacznikiem HTML – <td>. Nasze pętlę działają teraz tak. Znajdowany jest 1 wiersz, potem pętla dodaje do listy wszystkie napotkane w wierszu wartości ze znaczników <th>, znaczniki <th> się kończą i kończy się wiersz. Znajdowany jest 2 wiersz, potem pętla dodaje do listy wszystkie napotkane w wierszu wartości ze znaczników <th> (jedna wartość), pętla się kończy, ale wiersz nie, zaczyna się druga pętla, która dodaje do listy wszystkie wartości znaczników <td>, wiersz się kończy itd. Gdy spojrzysz na kawałek działającego programu wszystko, co się dzieje w pętlach, powinno stać się jaśnieszje:
==================== RESTART: F:/python38/Web scraping 06.py ===================
['Rekordy maksymalnej temperatury [°C]', '9']
['Rekordy maksymalnej temperatury [°C]', '9', '11']
['Rekordy maksymalnej temperatury [°C]', '9', '11', '18']
['Rekordy maksymalnej temperatury [°C]', '9', '11', '18', '26']
['Rekordy maksymalnej temperatury [°C]', '9', '11', '18', '26', '30']
['Rekordy maksymalnej temperatury [°C]', '9', '11', '18', '26', '30', '32']
['Rekordy maksymalnej temperatury [°C]', '9', '11', '18', '26', '30', '32', '37']
['Rekordy maksymalnej temperatury [°C]', '9', '11', '18', '26', '30', '32', '37', '35']
['Rekordy maksymalnej temperatury [°C]', '9', '11', '18', '26', '30', '32', '37', '35', '32']
['Rekordy maksymalnej temperatury [°C]', '9', '11', '18', '26', '30', '32', '37', '35', '32', '25']
['Rekordy maksymalnej temperatury [°C]', '9', '11', '18', '26', '30', '32', '37', '35', '32', '25', '16']
['Rekordy maksymalnej temperatury [°C]', '9', '11', '18', '26', '30', '32', '37', '35', '32', '25', '16', '11 ']
['Rekordy maksymalnej temperatury [°C]', '9', '11', '18', '26', '30', '32', '37', '35', '32', '25', '16', '11 ', '37']
['Średnie temperatury w dzień [°C]', '-1']
['Średnie temperatury w dzień [°C]', '-1', '-1']
['Średnie temperatury w dzień [°C]', '-1', '-1', '4']
['Średnie temperatury w dzień [°C]', '-1', '-1', '4', '12']
['Średnie temperatury w dzień [°C]', '-1', '-1', '4', '12', '17']
['Średnie temperatury w dzień [°C]', '-1', '-1', '4', '12', '17', '22']Jeśli cofniemy print poza wewnętrzną pętlę, zobaczymy skumulowany efekt:
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
for wiersz in tabela.findAll("tr"):
komorki_wiersza = []
for komorka_naglowka in wiersz.findAll("th"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
for komorka_naglowka in wiersz.findAll("td"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
print(komorki_wiersza)
==================== RESTART: F:/python38/Web scraping 06.py ===================
['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi', 'Maj', 'Cze', 'Lip', 'Sie', 'Wrz', 'Paź', 'Lis', 'Gru', 'Roczna']
['Rekordy maksymalnej temperatury [°C]', '9', '11', '18', '26', '30', '32', '37', '35', '32', '25', '16', '11 ', '37']
['Średnie temperatury w dzień [°C]', '-1', '-1', '4', '12', '17', '22', '23', '23', '19', '13', '5', '2 ', '12']
['Średnie temperatury w nocy [°C]', '-5', '-7', '-3', '2', '7', '12', '14', '13', '9', '4', '0', '-2 ', '4']
['Rekordy minimalnej temperatury [°C]', '-25', '-27', '-17', '-6', '-3', '3', '7', '8', '1', '-6', '-10', '-17 ', '-27']
['Opady [mm] ', '58.4', '43.2', '33', '33', '30.5', '73.7', '88.9', '61', '38.1', '35.6', '45.7', '63.5 ', '604,5']
['Źródło: Weatherbase[10] 14.12.2008']
>>> Pozostaje zrobić jeszcze jedną rzecz. Zamiast nadpisywać listę za każdym razem, chcemy taką listę wartości zapisać na kolejnej liście. Czyli utworzyć listę list. Nie jest to nic trudnego. Popatrz na przykład w terminalu IDLE:
>>> lista_list = []
>>> lista_1 = ["sty", "lut", "mar"]
>>> lista_2 = [10, 6, 11]
>>> lista_list.append(lista_1)
>>> print(lista_list)
[['sty', 'lut', 'mar']]
>>> lista_list.append(lista_2)
>>> print(lista_list)
[['sty', 'lut', 'mar'], [10, 6, 11]]W przykładzie definiujemy pustą listę, oraz dwie listy z danymi. W następnych linijkach, metodą .append() dodajemy listy zdeklarowane pod zmiennymi i drukujemy zmienną lista_list. Jak widzisz lista_list składa się z dwóch list.
Zastosujmy taką samą logikę w naszym programie! Wprowadź zmiany i sprawdź czy będą takie jak w poniższym przykładzie.
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
wiersze = []
for wiersz in tabela.findAll("tr"):
komorki_wiersza = []
for komorka_naglowka in wiersz.findAll("th"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
for komorka_naglowka in wiersz.findAll("td"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
wiersze.append(komorki_wiersza)
print(wiersze)
Komentarze
Zanim omówimy program, musimy zadbać o jego większą czytelność. Jednym ze sposobów poprawy czytelności jest pisanie komentarzy wyjaśniających co dany kawałek kodu programu robi. Wszystkie komentarze w Pythonie zaczynają się od znaku #. Wszystko, co znajduje się w linijce zaczynające się od # jest pomijane przez Pythona. Komentarze za to nie są pomijane przez czytającego kod. Pisząc komentarze masz jasność np. do czego służy pętla. Bez dokładnego analizowania jej linijka po linijce możesz pętlę zrozumieć i wykorzystać w innym projekcie, innym programie. Popatrz na zmodyfikowany kod programu:
from urllib.request import urlopen
from bs4 import BeautifulSoup
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
wiersze = []
#Dla każdego wiersza
for wiersz in tabela.findAll("tr"):
komorki_wiersza = []
#Dla każdej komórki w wierszu
for komorka_naglowka in wiersz.findAll("th"):
#Dodaj wartość komórki do listy
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
for komorka_naglowka in wiersz.findAll("td"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
#Dodaj listę komórek wiersza do listy wierszy
wiersze.append(komorki_wiersza)
print(wiersze)
Prawda, że czytelniej? Jeśli nie, napisz takie komentarze, które są dla Ciebie zrozumiałe. Uruchom program, zobaczmy efekt:
================================= RESTART: F:/python38/Web scraping 06.py ================================
[['Miesiąc', 'Sty', 'Lut', 'Mar', 'Kwi', 'Maj', 'Cze', 'Lip', 'Sie', 'Wrz', 'Paź', 'Lis', 'Gru', 'Roczna'], ['Rekordy maksymalnej temperatury [°C]', '9', '11', '18', '26', '30', '32', '37', '35', '32', '25', '16', '11 ', '37'], ['Średnie temperatury w dzień [°C]', '-1', '-1', '4', '12', '17', '22', '23', '23', '19', '13', '5', '2 ', '12'], ['Średnie temperatury w nocy [°C]', '-5', '-7', '-3', '2', '7', '12', '14', '13', '9', '4', '0', '-2 ', '4'], ['Rekordy minimalnej temperatury [°C]', '-25', '-27', '-17', '-6', '-3', '3', '7', '8', '1', '-6', '-10', '-17 ', '-27'], ['Opady [mm] ', '58.4', '43.2', '33', '33', '30.5', '73.7', '88.9', '61', '38.1', '35.6', '45.7', '63.5 ', '604,5'], ['Źródło: Weatherbase[10] 14.12.2008']]
>>> Teraz mamy gotową listę list, każda lista prezentuje wartości jednego wiersza tabeli. Taką listę z łatwością wyeksportujesz pliku
Eksport do pliku .csv
Plik .csv, to plik w którym poszczególne wartości są rozdzielane przecinkami. Jest to bardzo popularny format zapisywania danych tabelarycznych. Eksport do .csv nie jest obsługiwany przez standardowo załadowane funkcje Pythona. Musisz odpowiedni moduł doimportować (ale nie musisz go instalować), ten moduł nazywa się po prostu csv. Następnie otworzysz/utworzysz pusty plik, zapiszesz listę list do pustego pliku i na końcu plik zamkniesz. Zobacz jak to się robi, pamiętaj by pisać kod a nie czytać go, łatwiej przyswoisz nowe umiejętności:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
wiersze = []
#Dla każdego wiersza
for wiersz in tabela.findAll("tr"):
komorki_wiersza = []
#Dla każdej komórki w wierszu
for komorka_naglowka in wiersz.findAll("th"):
#Dodaj wartość komórki do listy
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
for komorka_naglowka in wiersz.findAll("td"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
#Dodaj listę komórek wiersza do listy wierszy
wiersze.append(komorki_wiersza)
#Zapisz dane do pliku
plik = open("pogoda_radom.csv", "w")
csv.writer(plik).writerows(wiersze)
plik.close()
W 3 linijce importujesz potrzebną bibliotekę, obsługującą zapis danych w plikach .csv.
W 24 linijce pod zmienną plik podstawiasz funkcję open(). Funkcja open() ma w tym wypadku 2 argumenty: nazwę pliku wraz z rozszerzeniem, podaną w cudzysłowach oraz „w”, co oznacza, że plik otwierasz z uprawnieniami do zapisu (write). Nazwa funkcji open() może być nieco myląca, funkcja nie potrzebuje jakiegoś pustego pliku by mogła go otworzyć, jeśli pliku nie znajdzie, utworzy go sama. Pierwszy argument funkcji open(), to nazwa pliku. Drugi argument, to sposób otwarcia/utworzenia pliku. "w" od Write, znaczy, że potrzebujemy do pliku coś zapisać.
W 25 linijce używasz funkcji writer() podając jako argument zmienną plik, czyli chcesz coś zapisać do wcześniej zdefiniowanego pliku, potem dodajesz metodę .writerows(), podając jako argument zmienną wiersze, czyli mówisz Pythonowi co chcesz do tego pliku zapisać, w naszym przypadku jest to zmienna wiersze.
W 26 linijce zamykasz plik metodą .close(). Zamykanie jest bardzo ważne, bez tej linijki nic się w pliku tak na prawdę nie zapisze, nie ma autozapisu, zamknięcie jest odpowiednikiem „Zapisz” z popularnych programów.
Zobaczmy efekt:
==================== RESTART: F:\python38\Web scraping 06.py ===================
>>> UWAGA w Python 3.9 zamiast wyniku zobaczysz błąd:
Traceback (most recent call last):
File "H:/python39/Scripts/skasuj.py", line 25, in <module>
csv.writer(plik).writerows(wiersze)
File "H:\python39\lib\encodings\cp1250.py", line 19, in encode
return codecs.charmap_encode(input,self.errors,encoding_table)[0]
UnicodeEncodeError: 'charmap' codec can't encode character '\u2212' in position 74: character maps to <undefined>Bład ten, UnicodeEncodeError:, w największej ogólności mówi, że Python nie wie co zrobić z jakimś znakiem/literą, bo nie odpowiada to domyślnemu kodowaniu. Dodajmy do funkcji open() argument odpowiadający za podanie kodowania encoding=. W naszym przypadku będzie to utf-8. Zmieniony program wygląda tak:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
wiersze = []
#Dla każdego wiersza
for wiersz in tabela.findAll("tr"):
komorki_wiersza = []
#Dla każdej komórki w wierszu
for komorka_naglowka in wiersz.findAll("th"):
#Dodaj wartość komórki do listy
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
for komorka_naglowka in wiersz.findAll("td"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
#Dodaj listę komórek wiersza do listy wierszy
wiersze.append(komorki_wiersza)
#Zapisz dane do pliku
plik = open("pogoda_radom.csv", "w", encoding="utf-8")
csv.writer(plik).writerows(wiersze)
plik.close()
Tym razem efekt działania programu jest zupełnie gdzie indziej, w folderze na Twoim komputerze. W którym? Najprawdopodobniej w tym, w którym jest zainstalowany Python. Zawsze możesz sprawdzić, który folder jest folderem „aktywnym” dla twojego Pythona.
os.getcwd()
Zrobisz to za pomocą funkcji .getcwd() z modułu os. Popatrz jakie to proste:
>>> import os
>>> os.getcwd()
'F:\\python38'
>>> Przejdź do odpowiedniego katalogu, odnajdź plik. Kliknij na nim prawym klawiszem i otwórz w programie typu notatnik:
Efekt będzie mniej więcej taki:
Miesiąc,Sty,Lut,Mar,Kwi,Maj,Cze,Lip,Sie,Wrz,Paź,Lis,Gru,Roczna
Rekordy maksymalnej temperatury [°C],9,11,18,26,30,32,37,35,32,25,16,11 ,37
Średnie temperatury w dzień [°C],-1,-1,4,12,17,22,23,23,19,13,5,2 ,12
Średnie temperatury w nocy [°C],-5,-7,-3,2,7,12,14,13,9,4,0,-2 ,4
Rekordy minimalnej temperatury [°C],-25,-27,-17,-6,-3,3,7,8,1,-6,-10,-17 ,-27
Opady [mm] ,58.4,43.2,33,33,30.5,73.7,88.9,61,38.1,35.6,45.7,63.5 ,"604,5"
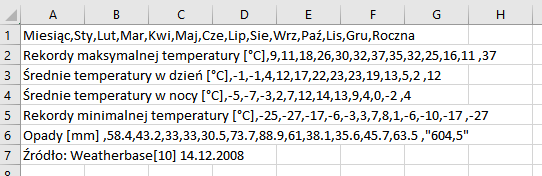
Źródło: Weatherbase[10] 14.12.2008Jak widzisz każda wartość jest rozdzielona przecinkami a każdy wiersz zaczyna się w nowej linijce. Pewnie widzisz też niekonsekwencję autora tabeli, dziesiąte części mm wartości opadów oznaczane są kropkami, ale suma roczna ma przecinek. Takie „drobnostki” powodują, że web scraping wymaga sporej uwagi od Ciebie a od pisanego programu sporej elastyczności.
W tym przykładzie widzisz zupełnie zbędne puste linijki. Nic nie szkodzi, zaraz to naprawimy dodając argument newline = "" do funkcji open(). Argument ten wskazuje, że nie chcemy nowych linijek, nasza lista list „sama z siebie” zaczyna każdy wiersz w nowej linijce. Zobaczmy kod:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
wiersze = []
#Dla każdego wiersza
for wiersz in tabela.findAll("tr"):
komorki_wiersza = []
#Dla każdej komórki w wierszu
for komorka_naglowka in wiersz.findAll("th"):
#Dodaj wartość komórki do listy
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
for komorka_naglowka in wiersz.findAll("td"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
#Dodaj listę komórek wiersza do listy wierszy
wiersze.append(komorki_wiersza)
#Zapisz dane do pliku
plik = open("pogoda_radom.csv", "w", encoding ="utf-8", newline = "")
csv.writer(plik).writerows(wiersze)
plik.close()
I spójrz jak teraz wygląda plik:
Miesiąc,Sty,Lut,Mar,Kwi,Maj,Cze,Lip,Sie,Wrz,Paź,Lis,Gru,Roczna
Rekordy maksymalnej temperatury [°C],9,11,18,26,30,32,37,35,32,25,16,11 ,37
Średnie temperatury w dzień [°C],-1,-1,4,12,17,22,23,23,19,13,5,2 ,12
Średnie temperatury w nocy [°C],-5,-7,-3,2,7,12,14,13,9,4,0,-2 ,4
Rekordy minimalnej temperatury [°C],-25,-27,-17,-6,-3,3,7,8,1,-6,-10,-17 ,-27
Opady [mm] ,58.4,43.2,33,33,30.5,73.7,88.9,61,38.1,35.6,45.7,63.5 ,"604,5"
Źródło: Weatherbase[10] 14.12.2008Bomba! Jeśli masz Excel to pewnie cię kusi otwarcie pliku w nim? Śmiało, kliknij go dwa razy, lub otwórz w swój ulubiony sposób. Efekt powinien być taki:
Jeśli efekt jest inny (brak polskich znaków), musisz pobawić się kodowaniem i importem do excela (zakładka „Dane”-> Z pliku tekstowego/CSV) i wybrać kodowanie utf-8. Teraz wystarczy zaznaczyć całą pierwszą kolumnę, Wybrać zakładkę „Dane” i kliknąć „Tekst jako kolumny”:
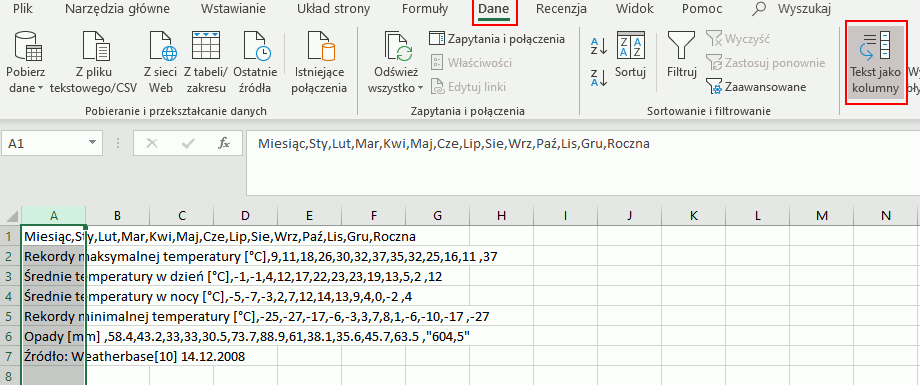
Po kliknięciu pokaże się nowe okno, zostaw zaznaczoną domyślną opcję „Rozdzielany” i kliknij „Dalej >”. W następnym oknie zaznacz w sekcji „Ograniczniki” pozycję „Przecinek” i kliknij „Dalej >”:
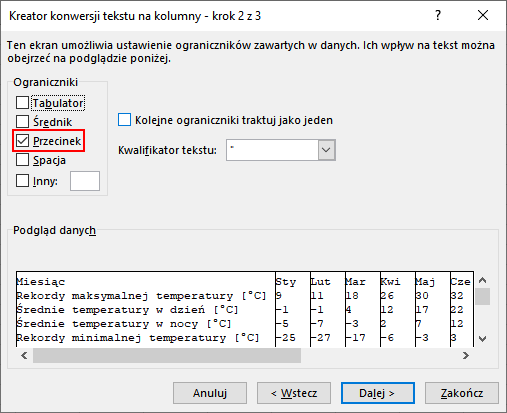
W następnym oknie kliknij „Zakończ”, efekt powinien być podobny do tego:

No i jest gotowa pełnoprawna tabela w Excel.
Masz jeszcze siłę? W tej części zajmujesz się stosunkowo łatwym przypadkiem, pobierasz dane z jednej strony z jednej tabeli i zapisujesz do pliku. Wyobraź sobie sytuację, gdy musisz do pliku zapisać różne informacje z różnych miejsc, i taki zapis pojawia się na początku, w środku i na końcu programu. Dla przejrzystości kodu i szybkości działania programu, zamykasz plik (.close()) dopiero na końcu kodu programu. W sytuacji, gdy program nie zakończy się prawidłowo, z powodu dowolnego błędu, przed metodą .close(), twoja praca nie zostanie zapisana. Metoda .close() nie wykona się. Na szczęście jest na to lekarstwo! Popatrz na zmodyfikowany kod.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://pl.wikipedia.org/wiki/Radom"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find("table", class_="wikitable collapsible")
wiersze = []
#Dla każdego wiersza
for wiersz in tabela.findAll("tr"):
komorki_wiersza = []
#Dla każdej komórki w wierszu
for komorka_naglowka in wiersz.findAll("th"):
#Dodaj wartość komórki do listy
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
for komorka_naglowka in wiersz.findAll("td"):
komorki_wiersza.append(komorka_naglowka.get_text().replace("\n", ''))
#Dodaj listę komórek wiersza do listy wierszy
wiersze.append(komorki_wiersza)
#Zapisz dane do pliku
with open("pogoda_radom.csv", "w", encoding = "utf-8", newline = "") as plik:
csv.writer(plik).writerows(wiersze)
W 24 linijce mamy na początku polecenie with, potem funkcję open() i słowa as plik. W uproszczeniu linijka ta mówi całkiem podobną rzecz, co w poprzedniej wersji. Mówisz Pythonowi, żeby otwarł plik pogoda_radom.csv i traktował go jako plik (poprzednio była to zmienna plik). Potem mamy dwukropek jak w pętli for.
25 linijka zaczyna się wcięta, wyżej był dwukropek, nie ma siły, trzeba wcinać. I zapisujemy wiersze do pliku.
Nie ma 26 linijki z poleceniem .close(), with zajmuje się tym.
Zadanie Domowe
Podążanie za instrukcjami, nawet jeśli je wszystkie wykonujesz samodzielnie, nie zrobi z ciebie programisty. Zadania domowe mogą wydawać się na początku trudne. Tu nie ma rozwiązania podanego na talerzu, użyj dowolnych źródeł, by znaleźć odpowiedź.
- Znajdź sposób, by Python zapisał plik .csv nie rozdzielany przecinkami a średnikami. Otwórz go w Excel, jest jakaś różnica?
- Odczytaj zapisany plik za pomocą Pythona, wydrukuj każdy wiersz jako listę.