
Czujesz już się pewny w Web scrapingu? Jesteś gotowy na pierwsze zlecenie? Zabawmy się w odgrywanie ról. Zgłasza się do Ciebie zleceniodawca:
„Pani/Panie Skraper,
Trafiłem na taki link: https://inferiordatascience.com/odmiana1/
Jest tam pełna informacja na temat jednej z odmian roślin, których usilnie poszukuję. Zawarte tam informacje pozwolą mi zdobyć tą odmianę! Takich odmian powinno być 10. Nie za bardzo umiem w komputery i nie wiem gdzie znaleźć resztę i nie wiem jak długo te informacje będą dostępne. Czy zbierzesz te wszystkie informacje dla mnie w czytelnej formie? Szwagier mówi, że najlepiej zapisywać tabele w MajSQL, ale tabelki Excel powinny mi wystarczyć. Za wykonane zadanie czeka cię nagroda w postaci trzycyfrowej satysfakcji.
Pozdrawiam,
Fanatyk odmian”
Pierwsze, co zrobimy to otworzymy stronę podaną w mailu. Gdy na serio zajmiesz się web scrapingiem, nie raz spotkasz się z koniecznością zebrania danych na tematy w których, być może, kiepsko się orientujesz. Nic nie szkodzi, do odważnych świat należy. Popatrz, na podanej stronie są 4 tabele.
Pierwsza tabela zawiera nazwy po polsku, angielsku i łacinie (Wikipedia ci w takim wnioskowaniu pomoże).
Druga tabela zawiera nazwy, status nazwy i kilka dat. Jak widać przy odmianach nazwy są bardzo ważne, skoro tabela jest tak rozbudowana.
Trzecia tabela zawiera informacje o statusie w rejestrze i księdze ochrony i czy można tą odmianą obracać. Jak widać nie wszystkie informacje są wypełnione.
Czwarta tabela to zestaw danych adresowych i nazw firm, które mają coś wspólnego z daną odmianą.
Dla Ciebie dane to dane i musisz je zapisać w jak najlepszy i najbardziej czytelny sposób. Oczywiście znajomość zagadnienia ułatwi ci życie, ale brak wiedzy na temat odmian nie jest przeszkodą.
Przeanalizujmy jeszcze adres strony. Wygląda on tak: https://inferiordatascience.com/odmiana1/. Co stanie się gdy zamienisz 1 na 2? Czy coś jest pod adresem https://inferiordatascience.com/odmiana2/? Jest! Czyli zadanie będzie bardzo proste. 10 stron na każdej 4 tabele. Nic trudnego, już wiesz jak pobierać dane z tabel. Cały ten proces podzielimy na kilka mniejszych zadań:
- Zapisanie tabel z pojedynczej strony
- Dopisanie do plików z tabelami tabel z kolejnych stron
- Sprawdzenie co to jest MajSQL i zapisanie danych w tym czymś.
Zapis tabel z pojedynczej strony
Z tym zadaniem sobie na pewno poradzisz. To czego potrzebujesz na początek to znalezienie jakiegoś identyfikatora odróżniającego poszczególne tabele. Zobaczmy jak wygląda id pierwszej tabeli (kliknij prawym klawiszem na treści tabeli i wybierz z menu opcję „Zbadaj”), zapisane przy znaczniku HTML <table>:
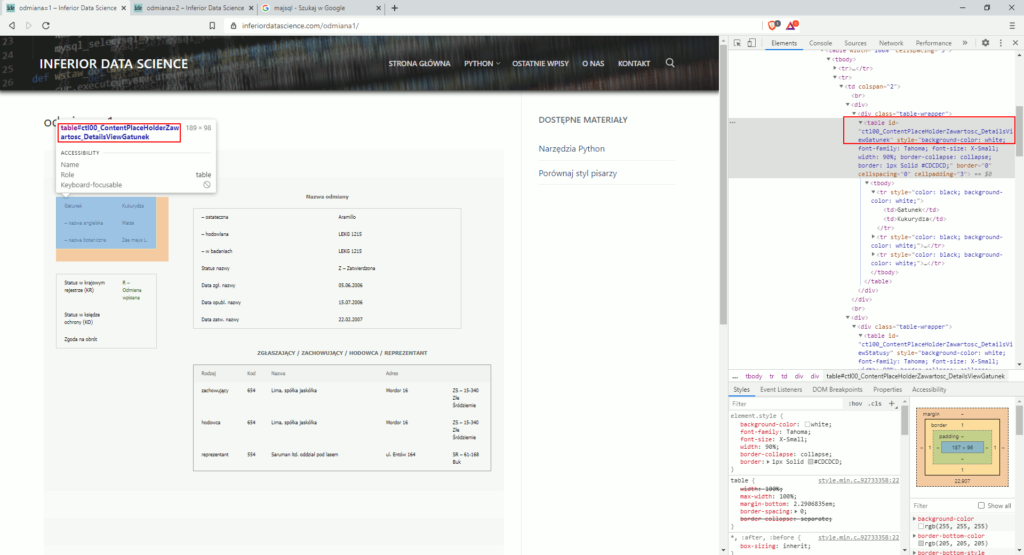
Na screenie wiele nie widać, ale id tabeli to „ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek”. W dodatku tabela ma dane zapisane między znacznikami <td>, nie ma żadnych <th> co uprości nasz program. Przetestujmy kilka pomysłów na zapis tabel. Od najprostszych do bardziej zaawansowanych.
Zapis każdej z tabeli osobno do pliku .csv
Zróbmy zapis w najszybszy możliwy sposób. Każda wartość tabeli pojawi się w kolejnej „komórce” pliku .csv. Każdą wartość, bez rozróżniania czy jest to nagłówek czy nie. W tym mamy wprawę. Napisz program i porównaj go z zaproponowanym poniżej.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://inferiordatascience.com/odmiana1/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find\
("table", id="ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek")
komorki= []
#dla każdej wartości wpisanej w znaczniki <td>
for komorka_wiersza in tabela.findAll("td"):
#dodaj je do listy zmiennej komorki
komorki.append(komorka_wiersza.get_text().replace("\n", ''))
print(komorki)
#Zapisz dane do pliku
with open("odmiana1tabela1.csv", "w") as plik:
csv.writer(plik).writerows(komorki)
W 8 linijce wyszukujemy znacznika HTML <table>, którego id jest równe nazwie tabeli, znalezionej na stronie. Linijka kodu jest całkiem długa, dlatego używamy backslash \ by treść przenieść do kolejnej linijki bez utraty ciągłości linijki.
W 11 linijce definiujemy pustą listę zapisaną pod zmienna komorki. Każdą daną traktujemy identycznie, dlatego potrzebna nam tylko jedna lista.
W 13 linijce zaczyna się pętla wyszukująca wartości tabeli i zapisująca je na liście.
W 17 linijce drukujemy listę, by upewnić się, że wszystko jest ok.
W 20 i 21 linijce zapisujemy do pliku .csv listę z danymi. Zobaczmy działanie programu:
==================== RESTART: F:/python38/Web scraping 07.py ===================
['Gatunek', 'Kukurydza', '– nazwa angielska', 'Maize', '– nazwa botaniczna', 'Zea mays L.']
>>> Tu wszystko wygląda ok. Zobaczmy jeszcze plik:
G,a,t,u,n,e,k
K,u,k,u,r,y,d,z,a
–, ,n,a,z,w,a, ,a,n,g,i,e,l,s,k,a
M,a,i,z,e
–, ,n,a,z,w,a, ,b,o,t,a,n,i,c,z,n,a
Z,e,a, ,m,a,y,s, ,L,.Tu już nie jest tak różowo, coś poszło nie tak. Nasze dane są aż za bardzo rozdzielone na komórki. Wszystkiemu winna użyta metoda .writerows(), służy ona do zapisu danych dwuwymiarowych, czyli w naszym przypadku do zapisu listy list. Ta sama metoda .writerows() otrzymując jako dane źródłowe pojedynczą listę, „potnie” na osobne komórki każdą literę wyrazu. Musimy zmienić metodę na taką, która zapisuje dane jednowymiarowo, czyli jeden wiersz. Metoda ta nazywa się .writerow()(writerows bez s). Zmieńmy kod:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://inferiordatascience.com/odmiana1/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find\
("table", id="ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek")
komorki= []
#dla każdej wartości wpisanej w znaczniki <td>
for komorka_wiersza in tabela.findAll("td"):
#dodaj je do listy zmiennej komorki
komorki.append(komorka_wiersza.get_text().replace("\n", ''))
print(komorki)
#Zapisz dane do pliku
with open("odmiana1tabela1.csv", "w") as plik:
csv.writer(plik).writerow(komorki)
Działanie programu zmieniło się w wygenerowanym pliku .csv:
Gatunek,Kukurydza,– nazwa angielska,Maize,– nazwa botaniczna,Zea mays L.Już mamy jakiś sensowny początek. Zauważ, że brakuje nam identyfikatora wskazującego czego te dane dotyczą. Dopiszmy go ręcznie:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://inferiordatascience.com/odmiana1/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela = html.find\
("table", id="ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek")
komorki= ["odmiana1"]
#dla każdej wartości wpisanej w znaczniki <td>
for komorka_wiersza in tabela.findAll("td"):
#dodaj je do listy zmiennej komorki
komorki.append(komorka_wiersza.get_text().replace("\n", ''))
print(komorki)
#Zapisz dane do pliku
with open("odmiana1tabela1.csv", "w") as plik:
csv.writer(plik).writerow(komorki)
W 11 linijce zamiast pustej listy utworzyliśmy listę już z jednym elementem. Efekt porgramu:
==================== RESTART: F:\python38\Web scraping 07.py ===================
['odmiana1', 'Gatunek', 'Kukurydza', '– nazwa angielska', 'Maize', '– nazwa botaniczna', 'Zea mays L.']
>>> I plik .csv też się zmienia:
odmiana1,Gatunek,Kukurydza,– nazwa angielska,Maize,– nazwa botaniczna,Zea mays L.Jedną tabelę mamy załatwioną. Dodajmy pozostałe 3:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://inferiordatascience.com/odmiana1/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela1 = html.find\
("table", id="ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek")
tabela2 = html.find\
("table", id="ctl00_ContentPlaceHolderZawartosc_DetailsViewNazwy")
tabela3 = html.find\
("table", id="ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy")
tabela4 = html.find\
("table", id="ctl00_ContentPlaceHolderZawartosc_GridViewHodowcyKR")
#zapis danych z 1 tabeli
komorki= ["odmiana1"]
for komorka_wiersza in tabela1.findAll("td"):
komorki.append(komorka_wiersza.get_text().replace("\n", ''))
with open("odmiana1tabela1.csv", "w") as plik:
csv.writer(plik).writerow(komorki)
#zapis danych z 2 tabeli
komorki= ["odmiana1"]
for komorka_wiersza in tabela2.findAll("td"):
komorki.append(komorka_wiersza.get_text().replace("\n", ''))
with open("odmiana1tabela2.csv", "w") as plik:
csv.writer(plik).writerow(komorki)
#zapis danych z 3 tabeli
komorki= ["odmiana1"]
for komorka_wiersza in tabela3.findAll("td"):
komorki.append(komorka_wiersza.get_text().replace("\n", ''))
with open("odmiana1tabela3.csv", "w") as plik:
csv.writer(plik).writerow(komorki)
#zapis danych z 4 tabeli
komorki= ["odmiana1"]
for komorka_wiersza in tabela4.findAll("td"):
komorki.append(komorka_wiersza.get_text().replace("\n", ''))
with open("odmiana1tabela4.csv", "w") as plik:
csv.writer(plik).writerow(komorki)
Jak już pewnie się domyślasz, przedstawiony program jest wybitnie kiepski. W linijkach 8-15 i 18-47 jest zapisane prawie to samo. Zajmijmy się najpierw pozyskaniem id tabel, żeby nie musieć ich podawać za każdym razem. Niech nasz program sam te id wyszuka i wykorzysta. Zacznijmy pisanie!
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://inferiordatascience.com/odmiana1/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele tabelę
tabele = html.findAll("table")
print(tabele)
W 10 linijce pod zmienną tabele podstawiasz wszystkie tabele (znacznik HTML table) wyszukane na stronie z wykorzystaniem metody .findAll(). W 12 linijce w ramach kontroli drukujemy to co udało się znaleźć. Zobaczmy efekt:
==================== RESTART: F:\python38\Web scraping 07.py ===================
[<table cellspacing="5" width="100%">
<tbody>
<tr>
<td colspan="4"><span id="ctl00_ContentPlaceHolderZawartosc_LabelTytul" style="color: #666666; font-weight: bold;">INFORMACJE O ODMIANIE</span> <span id="ctl00_ContentPlaceHolderZawartosc_LabelNazwaOdm" style="color: #006600; font-weight: bold;">Aramillo</span></td>
</tr>
<tr>
<td colspan="2"><br/>
<div>
(...)łączenie stringów oraz fstring
Zanim przejdziemy dalej, poznasz przyjemny sposób wstawiania zmiennych do stringa. Popatrz na taki przykład:
imie = "Makary"
nazwisko = "Wojtaszuk"
wiek = 22
zamieszkaly = "Krakowa"
print("Kolejnym uczestnikiem jest " + imie + " " + nazwisko + " lat " + str(wiek) + " mieszkaniec " + zamieszkaly)
W linijkach 1-4 definiujemy sobie zmienne tekstowe.
W linijce 6 drukujemy te zmienne wraz z dodatkowymi stringami. Jak widzisz, wszystko co nie jest podstawione pod zmienną wpisujemy w cudzysłowy a zmienne i stringi łączymy znakiem +, dodatkowo zmienna wiek, która jest liczbą całkowitą musiała zostać zmieniona na string funkcją str() (sprawdź co się stanie, jeśli nie użyjesz funkcji str()). Zobaczmy efekt:
==================== RESTART: F:\python38\Web scraping 07.py ===================
Kolejnym uczestnikiem jest Makary Wojtaszuk lat 22 mieszkaniec Krakowa
>>>Taki sam efekt można uzyskać w nieco inny sposób:
imie = "Makary"
nazwisko = "Wojtaszuk"
wiek = 22
zamieszkaly = "Krakowa"
print("Kolejnym uczestnikiem jest", imie, nazwisko, "lat", wiek, "mieszkaniec", zamieszkaly)
Zmieniła się jedynie 6 linijka. Zamiast znaku plus + używam przecinków , . Zauważ, że tym razem nie wpisałem spacji. Gdy używasz przecinków spacje dodają się automatycznie. Zauważ też, że zmienna wiek nie została zmieniona na string. Sprawdźmy jaki jest efekt:
==================== RESTART: F:\python38\Web scraping 07.py ===================
Kolejnym uczestnikiem jest Makary Wojtaszuk lat 22 mieszkaniec KrakowaOba te sposoby są stosowane w praktyce i często je spotkasz, ale już od dłuższego czasu Python obsługuje fstring (formatted string). Ta funkcjonalność poprawia przejrzystość i ułatwia podawanie „miksów” stringów i zmiennych. Napisz taki przykład:
imie = "Makary"
nazwisko = "Wojtaszuk"
wiek = 22
zamieszkaly = "Krakowa"
print(f"Kolejnym uczestnikiem jest {imie} {nazwisko} lat {wiek} mieszkaniec {zamieszkaly}")
Przyjrzyj się czym teraz różni się ostatnia linijka. Wyliczmy różnice:
- argument funkcji
print()zaczyna się od litery f - występują tylko dwa cudzysłowy, zaraz po f i na końcu argumentu
- zmienne są podawane w nawiasach klamrowych
{}
Zobaczmy jak teraz zachowa się nasz program:
==================== RESTART: F:\python38\Web scraping 07.py ===================
Kolejnym uczestnikiem jest Makary Wojtaszuk lat 22 mieszkaniec KrakowaW tym kursie będziemy się trzymać fstring. A teraz wróćmy do głównego wątku naszego webscrapingowego zadania!
Kolejnym krokiem będzie wydobycie jedynie id z każdej tabeli, użyjesz do tego metody .get(). Metoda .get() umożliwi ci pobranie wartości id z wyszukanych tabel. Popatrz na prosty przykład:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://inferiordatascience.com/odmiana1/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
tabela_1 = html.find\
("table", id="ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek")
print(tabela_1)
tytul_tabeli = tabela_1.get("id")
print(f"tytuł tabeli to: \n{tytul_tabeli}")
W 13 linijce używamy na jednej z tabel metody .get(), której argumentem jest id. Podstawiamy efekt działania metody pod zmienną tytul_tabeli.
W 14 linijce drukujemy tytuł tabeli, z użyciem nowo poznanego fstring. Sprawdźmy co otrzymaliśmy:
==================== RESTART: F:\python38\Web scraping 07.py ===================
<table border="0" cellpadding="3" cellspacing="0" id="ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek" style="background-color: white; font-family: Tahoma; font-size: X-Small; width: 90%; border-collapse: collapse; border: 1px Solid #CDCDCD;">
<tbody>
<tr style="color: black; background-color: white;">
<td>Gatunek</td>
<td>Kukurydza</td>
</tr>
<tr style="color: black; background-color: white;">
<td>– nazwa angielska</td>
<td>Maize</td>
</tr>
<tr style="color: black; background-color: white;">
<td>– nazwa botaniczna</td>
<td>Zea mays L.</td>
</tr>
</tbody>
</table>
tytuł tabeli to:
ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek
>>> Fajnie! Mamy tytuł, teraz wystarczy dodać pętlę, która wydrukuje nam wszystkie tytuły po kolei.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://inferiordatascience.com/odmiana1/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele tabelę
tabele = html.findAll("table")
for tab_id in tabele:
tytul_tabeli = tab_id.get("id")
print (tytul_tabeli)
W 12 linijce zaczynamy pętlę for, która będzie operować na wszystkich tabelach znalezionych na stronie.
W 13 linijce pod zmienną tytul_tabeli podstawiasz wartość tagu id z pierwszego znacznika HTML table.
W 14 linijce drukujesz znaleziony tytuł tabeli
Pętla kończy przebieg i zaczyna robić to samo z drugą tabelą itd. Zobaczmy efekt:
==================== RESTART: F:\python38\Web scraping 07.py ===================
None
ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek
ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy
ctl00_ContentPlaceHolderZawartosc_DetailsViewNazwy
ctl00_ContentPlaceHolderZawartosc_GridViewHodowcyKR
None
>>> Niby fajnie, ale mamy dwie wartości „None”. Co to znaczy? Jeśli się przyjrzysz źródle strony, zauważysz, że są tam tabele bez podanego id i dodatkowo bez zawartości. Jak widzisz, nie można oczekiwać, że strony są zrobione zgodnie ze sztuką i często znajdziesz tego typu kwiatki. Gdy twój program nie znajdzie id, nie może pobrać jego wartości i dlatego zwraca wartość „None”. Bądźmy porządni i usuńmy niepotrzebne tabele z naszego programu. Żeby to zrobić użyjesz instrukcji warunkowej if. Przyjrzyj się jej działaniu. To nic trudnego:
Instrukcja warunkowa if
cyfra = 2
if cyfra / 2 == 1:
print("dwójka")
W 1 linijce pod zmienną cyfra deklarujesz cyfrę 2.
W 3 linijce zaczyna się nasz warunek if. if cyfra / 2 oznacza: jeżeli zmienna nazwana cyfra dzielona przez 2. Potem mamy podwójny znaj równości ==, oznacza on jest równe. Nie można użyć pojedynczego =, jak juz doskonale wiesz = służy do deklarowania wartości dla zmiennych. Po znaku == jest cyfra 1 a na koniec znany ci już dwukropek :. Czyli cała linijka znaczy jeżeli cyfra dzielona przez 2 równa jest 1 to.
W 4 linijce zapisujemy to co ma się wykonać gdy warunek jest spełniony. Tak jak przy pętli for, wszystko co znajduje się po dwukropku i dotyczy instrukcji czy pętli jest wcięte (użyj tabulatora do wcięcia). Gdy warunek jest spełniony drukowany jest wyraz dwójka. Sprawdźmy działanie:
==================== RESTART: F:\python38\Web scraping 07.py ===================
dwójka
>>> Upewnijmy się, że program działa:
cyfra = 3
if cyfra / 2 == 1:
print("dwójka")
Efekt:
==================== RESTART: F:\python38\Web scraping 07.py ===================
>>> Nic się nie wydrukowało, znaczy warunek nie został spełniony. Warunki można odwrócić i zamiast „jest równe” podać „nie jest równe”. „Nie jest równe” oznaczamy !=. Napisz taki prosty program:
cyfra = 3
if cyfra / 2 != 1:
print("to nie jest dwójka")
W 3 linijce zamieniliśmy == na !=. Teraz przeczytać można ją tak jeżeli zmienna cyfra dzielona przez 2 nie jest równa 1 to:
W 4 linijce zapisujemy co ma się wydarzyć gdy warunek jest spełniony. Sprawdźmy działanie programu:
==================== RESTART: F:\python38\Web scraping 07.py ===================
to nie jest dwójka
>>> Oczywiście instrukcja warunkowa if może znajdować się w pętli for. Napiszmy prostą pętlę for, która drukuje kolejne elementy listy:
lista_cyfr = [1,2,3,4,5,6,7,8,9]
for cyfra in lista_cyfr:
print(cyfra)
Dla porządku wyświetlmy efekt:
==================== RESTART: F:\python38\Web scraping 07.py ===================
1
2
3
4
5
6
7
8
9
>>> Jeśli chciałbyś pozbyć się pierwszej cyfry z wydruku możesz zrobić to tak:
lista_cyfr = [1,2,3,4,5,6,7,8,9]
for cyfra in lista_cyfr:
if cyfra > 1:
print(cyfra)
W 3 linijce zaczynasz pętlę for, która pod zmienną cyfra podstawia po kolei każdy element listy lista_cyfr.
W 4 linijce zaczynasz instrukcję warunkową if (jest wcięta, bo ma obejmować swoim działaniem każdą z cyfr), która mówi, że jeżeli cyfra jest większa od 1 to:
W 5 linijce (wciętej o 2 tabulacje, bo wykonuje się ona dla każdej cyfry większej od 1) drukujemy wszystkie cyfry spełniające warunek. Zobaczmy działanie:
==================== RESTART: F:\python38\Web scraping 07.py ===================
2
3
4
5
6
7
8
9
>>> Teraz już wiesz jak pozbyć się None. To znaczy prawie wiesz. None oznacza brak wartości, jest słowem kluczowym, nie podajesz go w cudzysłowach. Napisz program, który wydrukuje tylko tytuły nazwanych tabel i sprawdź czy jest podobny do tego poniżej:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://inferiordatascience.com/odmiana1/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele tabelę
tabele = html.findAll("table")
#Wydrukuj tytuły nazwanych tabel
for tab_id in tabele:
tytul_tabeli = tab_id.get("id")
if tytul_tabeli != None:
print (tytul_tabeli)
W powyższym kodzie używasz tej samej logiki jakiej użyłeś w przykładach z listą cyfr.
W 15 linijce dodajemy instrukcję warunkową if, która sprawdza czy tag HTML table ma podaną wartość id.
Sprawdźmy efekt:
==================== RESTART: F:\python38\Web scraping 07.py ===================
ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek
ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy
ctl00_ContentPlaceHolderZawartosc_DetailsViewNazwy
ctl00_ContentPlaceHolderZawartosc_GridViewHodowcyKR
>>> Świetnie, napisany kod pozwoli uprościć pierwszą cześć programu zapisującego tabele. Jak zaraz zobaczysz zastosowanie instrukcji warunkowej if, upraszcza również drugą część:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
strona = "https://inferiordatascience.com/odmiana1/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele tabelę
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
#i jeśli id nie jest puste
if tytul_tabeli != None:
#przygotuj listę z identyfikatorem odmiany
komorki= ["odmiana1"]
#dodaj do listy wszystkie znajdujące się w tabeli
for komorka_wiersza in tabela.findAll("td"):
komorki.append(komorka_wiersza.get_text().replace("\n", ''))
#zapisz listę tabeli do pliku i nazwie = id
with open(f"{tytul_tabeli}.csv", "w") as plik:
csv.writer(plik).writerow(komorki)
Program jest już dość długi. Skupie się na wyjaśnieniu tylko kilku kluczowych elementów.
W 18 linijce z każdej tabeli pobieramy jej tytuł zapisany w id. A potem pobieramy dane z tabeli pamiętając o identyfikatorze odmiana1
W 27 linijce zapisujemy każdą z tabel do pliku .csv którego nazwa jest równa tytułowi tabeli. Sprawdź działanie programu. I popatrz jaki jest sprytny. Teraz niezależnie od liczby tabel na stronie, dane zawsze zostaną pobrane i zapisane (o ile tabela ma id). Po drugie program ma 28 linijek a nie 47 jak to było w pierwszej, pokracznej wersji.
To tyle w tej części, w następnej wybierzemy inne podejście do zapisywania danych w tabelach.
Zadanie Domowe
Podążanie za instrukcjami, nawet jeśli je wszystkie wykonujesz samodzielnie, nie zrobi z ciebie programisty. Zadania domowe mogą wydawać się na początku trudne. Tu nie ma rozwiązania podanego na talerzu, użyj dowolnych źródeł, by znaleźć odpowiedź.
- Z instrukcją warunkową if występuje często drugi warunek else. Napisz program, który sprawdza czy cyfra jest równa 2, jeśli tak, niech wydrukuje „to jest dwójka”, jeśli nie, niech wydrukuje „to nie jest dwójka”.
- Z instrukcją warunkową if, prócz else występuje jeszcze elif. Przygotuj listę cyfr od 1 do 9. Napisz program, który sprawdzi czy:
– cyfra jest dwójką i wydrukuje potwierdzenie (np. „to dwójka”)
– cyfra jest podzielna przez trzy i wydrukuje potwierdzenie (np. „podzielne przez 3”)
– nie jest dwójką ani cyfrą podzielną przez trzy (np. „ani takie ani takie”)