
Naszym celem jest umieszczenie na wykresie wszystkich najczęściej powtarzających się 3-gramów dla danego autora. Spójrzmy na dwa Dataframe z pomocą takiego programu:
import pandas as pd
JK1 = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
JK2 = "F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl"
df_JK1 = pd.read_pickle(JK1)
df_JK2 = pd.read_pickle(JK2)
print(df_JK1.head(10))
print(df_JK2.head(10))
Nic trudnego w kodzie nie ma, zobaczmy efekt:
======================== RESTART: F:/python38/wpis 17.py =======================
Trzygram JK Kiedy znow bede maly
606 nie wiem czy 18
3759 nie wiem co 13
6044 się zdaje że 12
1009 sam nie wiem 11
696 a ja się 10
6188 kiedy byłem dorosły 10
4931 a on się 9
1036 żeby się nie 8
13406 i nic nie 8
3231 w tej chwili 8
Trzygram JK Krol Macius na wyspie bezludnej
483 wasza królewska mość 27
44457 dziś popr forma 22
1196 waszej królewskiej mości 18
70 na bezludną wyspę 18
2723 na bezludnej wyspie 16
5868 nie wie maciuś 10
13473 pyta się maciuś 10
9133 co to za 10
44730 forma os lp 8
4163 i nic nie 8
No tak, pierwsze, co widzimy to źle przygotowane 3-gramy z książki „Król Maciuś na bezludnej wyspie”(nie bez powodu strona ma w nazwie inferior). Najpierw usuńmy wiersz 44457 i 44730, tak na prawdę powinniśmy przygotować Dataframe od nowa, ale jeszcze nie ćwiczyliśmy usuwania wierszy, jest ku temu okazja! Do usunięcia użyjemy funkcji drop(), a argumentem funkcji będzie wartość indeksu, całość zamkniemy w funkcji print()żeby zobaczyć efekt:
import pandas as pd
JK1 = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
JK2 = "F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl"
df_JK1 = pd.read_pickle(JK1)
df_JK2 = pd.read_pickle(JK2)
print(df_JK2.drop(44457).head(10))
W 8 linijce argumentem funkcji drop() jest numer indeksu, który chcemy usunąć z Dataframe, następnie wybieramy funkcją head() 10 pierwszych wierszy, całość jest drukowana funkcją print(). Popatrzmy:
======================== RESTART: F:/python38/wpis 17.py =======================
Trzygram JK Krol Macius na wyspie bezludnej
483 wasza królewska mość 27
1196 waszej królewskiej mości 18
70 na bezludną wyspę 18
2723 na bezludnej wyspie 16
5868 nie wie maciuś 10
13473 pyta się maciuś 10
9133 co to za 10
44730 forma os lp 8
4163 i nic nie 8
61 wcale się nie 8
>>> Pomysł działa, 3-gram „dziś popr forma” zniknął z Dataframe. Usuńmy jeszcze „forma os lp”:
import pandas as pd
JK1 = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
JK2 = "F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl"
df_JK1 = pd.read_pickle(JK1)
df_JK2 = pd.read_pickle(JK2)
print(df_JK2.drop(44457, 44730).head(10))
I zobaczmy efekt:
======================== RESTART: F:/python38/wpis 17.py =======================
Traceback (most recent call last):
File "F:/python38/wpis 17.py", line 8, in <module>
print(df_JK2.drop(44457, 44730).head(10))
File "F:\python38\lib\site-packages\pandas\core\frame.py", line 3990, in drop
return super().drop(
File "F:\python38\lib\site-packages\pandas\core\generic.py", line 3923, in drop
axis_name = self._get_axis_name(axis)
File "F:\python38\lib\site-packages\pandas\core\generic.py", line 420, in _get_axis_name
raise ValueError(f"No axis named {axis} for object type {cls}")
ValueError: No axis named 44730 for object type <class 'pandas.core.frame.DataFrame'>
>>> Ups. Błąd nie mówi wprost, co zrobiliśmy źle, ale ja powiem. Jeśli podajemy indeks więcej niż jednego wiersza, trzeba podać listę indeksów, a listy zamyka się w kwadratowych nawiasach []. Poprawmy program:
import pandas as pd
JK1 = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
JK2 = "F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl"
df_JK1 = pd.read_pickle(JK1)
df_JK2 = pd.read_pickle(JK2)
print(df_JK2.drop([44457, 44730]).head(10))
I zobaczmy efekt:
======================== RESTART: F:/python38/wpis 17.py =======================
Trzygram JK Krol Macius na wyspie bezludnej
483 wasza królewska mość 27
1196 waszej królewskiej mości 18
70 na bezludną wyspę 18
2723 na bezludnej wyspie 16
5868 nie wie maciuś 10
13473 pyta się maciuś 10
9133 co to za 10
4163 i nic nie 8
61 wcale się nie 8
5718 ale się nie 7
>>> Teraz spójrzmy jeszcze raz na poprawne Dataframe:
import pandas as pd
JK1 = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
JK2 = "F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl"
df_JK1 = pd.read_pickle(JK1)
df_JK2 = pd.read_pickle(JK2)
df_JK2.drop([44457, 44730], inplace = True)
print(df_JK1.head(10))
print(df_JK2.head(10))
W 7 linijce funkcją drop() pozbywamy się dwóch niepotrzebnych wierszy i dodajemy znany już argument inplace o wartości True, który dokonuję zmianę „w miejscu” bez konieczności definiowania Dataframe pod nową zmienną. Popatrzmy:
======================== RESTART: F:/python38/wpis 17.py =======================
Trzygram JK Kiedy znow bede maly
606 nie wiem czy 18
3759 nie wiem co 13
6044 się zdaje że 12
1009 sam nie wiem 11
696 a ja się 10
6188 kiedy byłem dorosły 10
4931 a on się 9
1036 żeby się nie 8
13406 i nic nie 8
3231 w tej chwili 8
Trzygram JK Krol Macius na wyspie bezludnej
483 wasza królewska mość 27
1196 waszej królewskiej mości 18
70 na bezludną wyspę 18
2723 na bezludnej wyspie 16
5868 nie wie maciuś 10
13473 pyta się maciuś 10
9133 co to za 10
4163 i nic nie 8
61 wcale się nie 8
5718 ale się nie 7
>>> Chcielibyśmy, by wszystkie 3-gramy znalazły się w jednym Dataframe wraz z liczbą wystąpień. Chcemy też jedną rzecz więcej, popatrz na 3-gram „i nic nie” w kolumnie Trzygram powinien pojawić się raz, ale częstość występowania powinna zostać zachowana dla obu książek, to w ten sposób zobaczymy czy podobne zwroty występują u wybranego pisarza w kolejnych książkach. Łączyć Dataframe można na wiele sposobów, przetestujmy kilka na naszym przykładzie.
Concat()
Concat() pozwala na dodanie danych z podobnych Dataframe. Przygotowane przez nas Dataframe są do siebie podobne, każde składa się z nienazwanego indeksu, kolumny nazwanej Trzygram, zawierającej dane typu string i z kolumny nazwanej w każdym Dataframe inaczej, ale danymi zawsze są liczby. Spróbujmy połączyć dwa Dataframe:
import pandas as pd
JK1 = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
JK2 = "F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl"
df_JK1 = pd.read_pickle(JK1).head(10)
df_JK2 = pd.read_pickle(JK2).head(10)
df_JK2.drop([44457, 44730], inplace = True)
print(df_JK1)
print(df_JK2)
df_JK1_JK2 = pd.concat([df_JK1, df_JK2])
print(df_JK1_JK2)
W 12 linijce definiujemy nową zmienną df_JK1_JK2, pod którą podstawiamy wynik działania funkcji conacat() na dwóch Dataframe df_JK1, df_JK2, argumentem jest lista zmiennych zawierających Dataframe. Zobaczmy efekt:
======================== RESTART: F:\python38\wpis 17.py =======================
Trzygram JK Kiedy znow bede maly
606 nie wiem czy 18
3759 nie wiem co 13
6044 się zdaje że 12
1009 sam nie wiem 11
696 a ja się 10
6188 kiedy byłem dorosły 10
4931 a on się 9
1036 żeby się nie 8
13406 i nic nie 8
3231 w tej chwili 8
Trzygram JK Krol Macius na wyspie bezludnej
483 wasza królewska mość 27
1196 waszej królewskiej mości 18
70 na bezludną wyspę 18
2723 na bezludnej wyspie 16
5868 nie wie maciuś 10
13473 pyta się maciuś 10
9133 co to za 10
4163 i nic nie 8
Trzygram ... JK Krol Macius na wyspie bezludnej
606 nie wiem czy ... NaN
3759 nie wiem co ... NaN
6044 się zdaje że ... NaN
1009 sam nie wiem ... NaN
696 a ja się ... NaN
6188 kiedy byłem dorosły ... NaN
4931 a on się ... NaN
1036 żeby się nie ... NaN
13406 i nic nie ... NaN
3231 w tej chwili ... NaN
483 wasza królewska mość ... 27.0
1196 waszej królewskiej mości ... 18.0
70 na bezludną wyspę ... 18.0
2723 na bezludnej wyspie ... 16.0
5868 nie wie maciuś ... 10.0
13473 pyta się maciuś ... 10.0
9133 co to za ... 10.0
4163 i nic nie ... 8.0
[18 rows x 3 columns]
>>>
Niewątpliwie coś się stało. Dataframe df_JK1_JK2 ma wszystkie dane, ale:
- pojawiło się tajemnicze
NaN, - 3-gram „i nic nie” jest dwa razy
- zamiast kolumny z liczbą występowania 3-gramów w JK Kiedy znow bede maly mamy wielokropek.
Zajmijmy się najpierw brakującą kolumną. Pamiętasz jak pisałem, że Pandas dba o to, żeby nie zarżnąć terminala wyświetlaniem zbyt dużej ilości danych? Tu właśnie jest efekt takiego zachowania, my musimy w naszym programie wymusić wyświetlanie większej liczby kolumn. Robi się to z użyciem funkcji set_option(), w której argumentem będzie display.max_columns wraz z wartością 3, chcemy wyświetlić 3 kolumny, nie licząc indeksu. Przetestujmy taki kod:
import pandas as pd
#wymuś wyświetlanie 3 kolumn
pd.set_option("display.max_columns", 3)
JK1 = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
JK2 = "F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl"
df_JK1 = pd.read_pickle(JK1).head(10)
df_JK2 = pd.read_pickle(JK2).head(10)
df_JK2.drop([44457, 44730], inplace = True)
df_JK1_JK2 = pd.concat([df_JK1, df_JK2])
print(df_JK1_JK2)
W 3 linijce jest ustawiona nasza opcja wyświetlania kolumn. Zobaczmy efekt:
============================================ RESTART: F:\python38\wpis 17.py ============================================
Trzygram JK Kiedy znow bede maly \
606 nie wiem czy 18.0
3759 nie wiem co 13.0
6044 się zdaje że 12.0
1009 sam nie wiem 11.0
696 a ja się 10.0
6188 kiedy byłem dorosły 10.0
4931 a on się 9.0
1036 żeby się nie 8.0
13406 i nic nie 8.0
3231 w tej chwili 8.0
483 wasza królewska mość NaN
1196 waszej królewskiej mości NaN
70 na bezludną wyspę NaN
2723 na bezludnej wyspie NaN
5868 nie wie maciuś NaN
13473 pyta się maciuś NaN
9133 co to za NaN
4163 i nic nie NaN
JK Krol Macius na wyspie bezludnej
606 NaN
3759 NaN
6044 NaN
1009 NaN
696 NaN
6188 NaN
4931 NaN
1036 NaN
13406 NaN
3231 NaN
483 27.0
1196 18.0
70 18.0
2723 16.0
5868 10.0
13473 10.0
9133 10.0
4163 8.0
>>>
Jeśli dobrze się przyjrzeć, to efekt został osiągnięty, mamy wszystkie 4 kolumny, z czego ostatnia jest wyświetlona w nowych linijkach a po tytule przedostatniej kolumny pojawia się charakterystyczny znak kontynuacji \. Jeśli zamarzyłoby ci się wyświetlenie wszystkich kolumn obok siebie, to musisz użyć jeszcze jednego argumentu w opcjach display.width, którego argumentem jest maksymalna liczba znaków wyświetlana w jednej linii. Nie będziemy liczyć znaków, podamy wartość 200 i zobaczymy, co z tego wyniknie. Poprawiony kod prezentuje się tak:
import pandas as pd
#wymuś wyświetlanie 3 kolumn i do 200 znaków w wierszach
pd.set_option("display.max_columns", 3, "display.width", 200)
JK1 = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
JK2 = "F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl"
df_JK1 = pd.read_pickle(JK1).head(10)
df_JK2 = pd.read_pickle(JK2).head(10)
df_JK2.drop([44457, 44730], inplace = True)
df_JK1_JK2 = pd.concat([df_JK1, df_JK2])
print(df_JK1_JK2)
A efekt działania jest taki:
============================================ RESTART: F:\python38\wpis 17.py ============================================
Trzygram JK Kiedy znow bede maly JK Krol Macius na wyspie bezludnej
606 nie wiem czy 18.0 NaN
3759 nie wiem co 13.0 NaN
6044 się zdaje że 12.0 NaN
1009 sam nie wiem 11.0 NaN
696 a ja się 10.0 NaN
6188 kiedy byłem dorosły 10.0 NaN
4931 a on się 9.0 NaN
1036 żeby się nie 8.0 NaN
13406 i nic nie 8.0 NaN
3231 w tej chwili 8.0 NaN
483 wasza królewska mość NaN 27.0
1196 waszej królewskiej mości NaN 18.0
70 na bezludną wyspę NaN 18.0
2723 na bezludnej wyspie NaN 16.0
5868 nie wie maciuś NaN 10.0
13473 pyta się maciuś NaN 10.0
9133 co to za NaN 10.0
4163 i nic nie NaN 8.0
>>> Nice! Pierwsza sprawa załatwiona. Przejdźmy do NaN. NaN oznaczają brakujące wartości. W bazach danych brakujące wartości oznaczane są NULL, w Excel to po prostu puste komórki. W naszym przykładzie NaN wyświetlają się prawidłowo, Dataframe z książki „Kiedy znów będę mały” nie ma kolumny JK Krol Macius na wyspie bezludnej, więc nie ma dla niej wartości. Dataframe z książki „Król Maciuś na wyspie bezludnej” nie ma kolumny JK Kiedy znow bede maly, więc nie ma dla niej wartości.
merge()
Dodanie Dataframe funkcją concat() nie spełniło naszych nadziei. Spróbujmy zamiast dodania złączyć dane za pomocą funkcji merge(). Tutaj musimy podać więcej argumentów, niż przy concat(). Popatrz na przykład:
import pandas as pd
#wymuś wyświetlanie 3 kolumn i do 200 znaków w wierszach
pd.set_option("display.max_columns", 3, "display.width", 200)
JK1 = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
JK2 = "F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl"
df_JK1 = pd.read_pickle(JK1).head(10)
df_JK2 = pd.read_pickle(JK2).head(10)
df_JK2.drop([44457, 44730], inplace = True)
df_JK1_JK2 = pd.merge(df_JK1, df_JK2, on = "Trzygram", how = "left")
print(df_JK1_JK2)
W funkcji merge() podajemy jako argument Dataframe, które chcemy złączyć, zauważ, że już nie są listą. Potem argumentem on wskazujemy kolumnę która będzie użyta do złączenia. Potem argumentem how należy wskazać metodę łączenia. W pierwszym przykładzie łączymy z użyciem kolumny Trzygram, metodą left. Co oznacza to left zaraz wytłumaczę, najpierw zobaczmy jaki jest wynik działania programu:
=================================================== RESTART: F:\python38\wpis 17.py ===================================================
Trzygram JK Kiedy znow bede maly JK Krol Macius na wyspie bezludnej
0 nie wiem czy 18 NaN
1 nie wiem co 13 NaN
2 się zdaje że 12 NaN
3 sam nie wiem 11 NaN
4 a ja się 10 NaN
5 kiedy byłem dorosły 10 NaN
6 a on się 9 NaN
7 żeby się nie 8 NaN
8 i nic nie 8 8.0
9 w tej chwili 8 NaN
>>>
Coś udało nam się osiągnąć. Jeśli dobrze się przyjrzysz wynikowi, zauważysz, że wyświetliłeś wszystkie 3-gramy z df_JK1 i te 3-gramy z df_JK2, które występują w df_JK1. Tak właśnie działa left w argumencie on. Wynikiem jest wszystko, co było w „lewym” Dataframe (bardziej „po lewej” zapisaliśmy df_JK1, pd.merge(df_JK1, df_JK2) i wartości z „prawego” Dataframe dla tych samych wierszy z kolumny Trzygram, które są w „lewym”. Popatrz na poniższe grafiki.
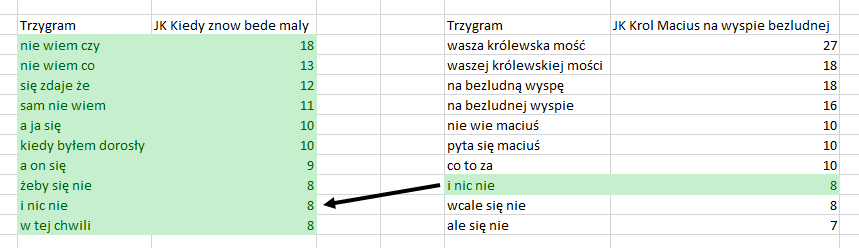
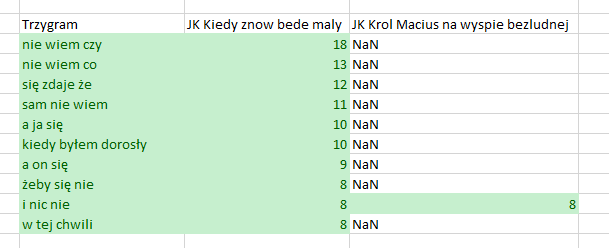
Zobaczmy, co się stanie jeśli zmienimy left na right:
import pandas as pd
#wymuś wyświetlanie 3 kolumn i do 200 znaków w wierszach
pd.set_option("display.max_columns", 3, "display.width", 200)
JK1 = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
JK2 = "F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl"
df_JK1 = pd.read_pickle(JK1).head(10)
df_JK2 = pd.read_pickle(JK2).head(10)
df_JK2.drop([44457, 44730], inplace = True)
df_JK1_JK2 = pd.merge(df_JK1, df_JK2, on = "Trzygram", how = "right")
print(df_JK1_JK2)
Zobaczmy efekt. A właściwie powinieneś odgadnąć jaki efekt będzie:
Trzygram JK Kiedy znow bede maly JK Krol Macius na wyspie bezludnej
0 i nic nie 8.0 8
1 wasza królewska mość NaN 27
2 waszej królewskiej mości NaN 18
3 na bezludną wyspę NaN 18
4 na bezludnej wyspie NaN 16
5 nie wie maciuś NaN 10
6 pyta się maciuś NaN 10
7 co to za NaN 10
>>> Tym razem mamy wszystkie wiersze z df_JK2 i tyllko te wiersze z df_JK1, które pokrywają się z df_JK2, widać to dobrze w pierwszym wierszu. Wynikiem jest wszystko co było z prawej – right (bardziej „po prawej” zapisaliśmy df_JK2, pd.merge(df_JK1, df_JK2). Popatrz na poniższe grafiki:
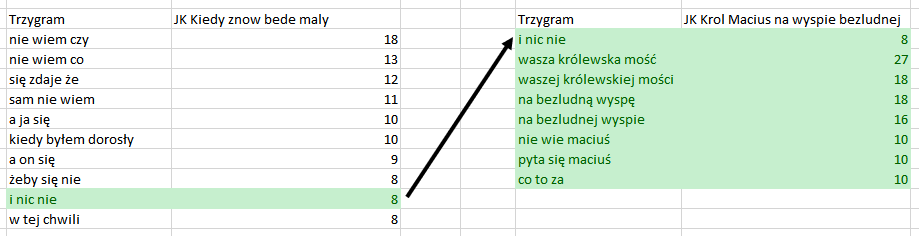
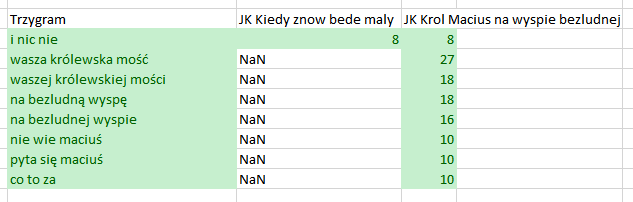
Zauważ, że przy metodzie right otrzymaliśmy 8 wierszy, dlaczego? Ano z df_JK2 usunęliśmy ręcznie dwa wiersze, który jest „prawym” i to on jest ważniejszy. Oba sposoby są przydatne w różnych sytuacjach, ale my chcemy wszystkie wartości z df_JK1 i wszystkie wartości z df_JK2. Do tego celu trzeba użyć wartości outer. Popatrz:
import pandas as pd
#wymuś wyświetlanie 3 kolumn i do 200 znaków w wierszach
pd.set_option("display.max_columns", 3, "display.width", 200)
JK1 = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
JK2 = "F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl"
df_JK1 = pd.read_pickle(JK1).head(10)
df_JK2 = pd.read_pickle(JK2).head(10)
df_JK2.drop([44457, 44730], inplace = True)
df_JK1_JK2 = pd.merge(df_JK1, df_JK2, on = "Trzygram", how = "outer")
print(df_JK1_JK2)
I wynik takiego programu:
=================================================== RESTART: F:\python38\wpis 17.py ===================================================
Trzygram JK Kiedy znow bede maly JK Krol Macius na wyspie bezludnej
0 nie wiem czy 18.0 NaN
1 nie wiem co 13.0 NaN
2 się zdaje że 12.0 NaN
3 sam nie wiem 11.0 NaN
4 a ja się 10.0 NaN
5 kiedy byłem dorosły 10.0 NaN
6 a on się 9.0 NaN
7 żeby się nie 8.0 NaN
8 i nic nie 8.0 8.0
9 w tej chwili 8.0 NaN
10 wasza królewska mość NaN 27.0
11 waszej królewskiej mości NaN 18.0
12 na bezludną wyspę NaN 18.0
13 na bezludnej wyspie NaN 16.0
14 nie wie maciuś NaN 10.0
15 pyta się maciuś NaN 10.0
16 co to za NaN 10.0
>>>
Jeśli nie jest dla Ciebie do końca jasne, co tu się dzieje, uruchom lekko zmodyfikowany program:
from os import listdir
import pandas as pd
pd.set_option("display.max_columns", 7, "display.width", 200)
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
dfJK = pd.read_pickle\
("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(10)
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(10)
dfJK = pd.merge(dfJK, df, on = "Trzygram", how = "outer")
print(dfJK)
W 14 linijce przesunąłem drukowanie Dataframe, by pokazywał się po każdym przejściu pętli, czyli z każdą nową kolumną.
W końcu mamy oczekiwany efekt, mamy wszystkie wartości dla kolumny Trzygram, bez powtórzeń, a liczebność „i nic nie” wyświetla się poprawnie, czyli ma takie wartości, jak w wyjściowych Dataframe. Teraz musimy znaleźć zgrabny sposób na połączenie top 10 3-gramów ze wszystkich książek Janusza Korczaka. By ułatwić sobie życie, najpierw musimy zrobić porządek z plikiem źródłowym Krol Macius na wyspie bezludnej.pkl, w którym nie usunąłem wcześniej przypisów. Można to zrobić poprzez modyfikację znanego już nam kodu:
import pandas as pd
#wymuś wyświetlanie 3 kolumn i do 200 znaków w wierszach
pd.set_option("display.max_columns", 3, "display.width", 200)
JK1 = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
JK2 = "F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl"
df_JK1 = pd.read_pickle(JK1).head(10)
df_JK2 = pd.read_pickle(JK2).head(10)
df_JK2.drop([44457, 44730], inplace = True)
df_JK2.to_pickle("F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl")
W 11 linijce plik z usuniętymi dwoma wierszami zastępuje oryginalny plik.
Przejdźmy do połączenia wszystkich Dataframe Janusza Korczaka w jeden Dataframe. Można to zrobić tak:
import pandas as pd
pd.set_option("display.max_columns", 7, "display.width", 200)
df1 = pd.read_pickle("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").\
head(10)
df2 = pd.read_pickle("F:\\python\\pickle\\JK Dzieci ulicy.pkl").\
head(10)
df3 = pd.read_pickle("F:\\python\\pickle\\JK Dziecko salonu.pkl").\
head(10)
df4 = pd.read_pickle("F:\\python\\pickle\\JK Kajtus Czarodziej.pkl").\
head(10)
df5 = pd.read_pickle("F:\\python\\pickle\\JK Kiedy znow bede maly.pkl").\
head(10)
df6 = pd.read_pickle("F:\\python\\pickle\\JK Krol Macius na wyspie bezludnej.pkl").\
head(10)
dfJK = pd.merge(df1, df2, on = "Trzygram", how = "outer")
dfJK = pd.merge(dfJK, df3, on = "Trzygram", how = "outer")
dfJK = pd.merge(dfJK, df4, on = "Trzygram", how = "outer")
dfJK = pd.merge(dfJK, df5, on = "Trzygram", how = "outer")
dfJK = pd.merge(dfJK, df6, on = "Trzygram", how = "outer")
print(dfJK)
Ta metoda oczywiście zadziała, ale co jeśli mamy 100 książek? Lepiej umieścić nasze łączenie w pętli. Zwróć uwagę, że funkcja merge() potrzebuje dokładnie dwóch Dataframe do działania. Zróbmy to krok po kroku:
from os import listdir
import pandas as pd
pd.set_option("display.max_columns", 7, "display.width", 200)
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
dfJK = pd.read_pickle("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(10)
print(dfJK)
W 7 linijce odczytujemy nasz pierwszy dataframe. Robimy to poza pętlą, pętla będzie dodawać do pierwszego kolejne 5. Upewnijmy się, że nasz kod działa:
======================================================================================== RESTART: F:\python38\wpis 17.py ========================================================================================
Trzygram JK Bankructwo malego Dzeka
3415 pani powiedziała że 11
6376 że się nie 8
6761 żeby się nie 8
33596 bo nie ma 7
19972 z mister taftem 7
2501 ale dżek nie 7
6803 to znaczy że 7
39081 bank dla dzieci 7
10163 do mister tafta 7
3947 na przyszły rok 7
>>>
Teraz musimy napisać pętlę, która uwzględni wszystkie pliki Janusza Korczaka za wyjątkiem JK Bankructwo malego Dzeka.pkl, tego pliku nie chcemy dodawać drugi raz. Spróbujmy dodać do pętli wszystkie pliki z 3-gramami Janusza Korczaka:
from os import listdir
import pandas as pd
pd.set_option("display.max_columns", 7, "display.width", 200)
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
dfJK = pd.read_pickle("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(10)
for plik in pliki_pickle:
if plik.startswith("JK"):
print(plik)
W 9 linijce zaczynamy pętlę w której użyta jest metoda .startswith(). jako Argument funkcji .startswith() podajemy string, od którego zaczyna się nazwa naszego pliku. Wiemy, że wszystkie pliki z 3-gramami Janusza Korczaka zaczynają się od JK. Sprawdźmy działanie programu:
======================== RESTART: F:\python38\wpis 17.py =======================
JK Bankructwo malego Dzeka.pkl
JK Dzieci ulicy.pkl
JK Dziecko salonu.pkl
JK Kajtus Czarodziej.pkl
JK Kiedy znow bede maly.pkl
JK Krol Macius na wyspie bezludnej.pkl
>>> Nasz kod można zapisać trochę inaczej:
from os import listdir
import pandas as pd
pd.set_option("display.max_columns", 7, "display.width", 200)
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
dfJK = pd.read_pickle("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(10)
for plik in pliki_pickle:
if plik.startswith("JK") == True:
print(plik)
W 9 linijce dopisaliśmy == True. Czyli napisaliśmy bardziej dosadnie „jeśli prawdą jest, że początek stringa plik to string JK” to:. Efekt będzie taki sam:
======================== RESTART: F:\python38\wpis 17.py =======================
JK Bankructwo malego Dzeka.pkl
JK Dzieci ulicy.pkl
JK Dziecko salonu.pkl
JK Kajtus Czarodziej.pkl
JK Kiedy znow bede maly.pkl
JK Krol Macius na wyspie bezludnej.pkl
>>> Wiedząc, że możemy testować tak warunki, to spróbumy podać w pętli if drugi warunek, który pozwoli pozbyć się JK Bankructwo malego Dzeka.pkl. Popatrz na poniższy kod:
from os import listdir
import pandas as pd
pd.set_option("display.max_columns", 7, "display.width", 200)
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
dfJK = pd.read_pickle("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(10)
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
print(plik)
W 9 linijce mamy teraz dwa warunki do sprawdzenia. Czy prawdą jest, że string zaczyna się od JK i (and) czy nie kończy się na a.pkl. Drugi warunek, z wykorzystaniem metody .endswith() pozwoli nam usunąć z pętli plik JK Bankructwo malego Dzeka.pkl. Użycie and, oznacza, że oba warunki muszą być spełnione, by zadanie pętli zostało wykonane. Sprawdźmy, czy nasze oczekiwania zostały spełnione:
======================== RESTART: F:\python38\wpis 17.py =======================
JK Dzieci ulicy.pkl
JK Dziecko salonu.pkl
JK Kajtus Czarodziej.pkl
JK Kiedy znow bede maly.pkl
JK Krol Macius na wyspie bezludnej.pkl
>>> O tak! Mamy już wszystkie klocki niezbędne do poskładania 6 Dataframe w jeden. Zróbmy to:
from os import listdir
import pandas as pd
pd.set_option("display.max_columns", 7, "display.width", 200)
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
dfJK = pd.read_pickle\
("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(10)
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(10)
dfJK = pd.merge(dfJK, df, on = "Trzygram", how = "outer")
print(dfJK)
W 7 linijce tworzymy zmienną dfJK, pod którą podstawiamy nasz pierwszy Dataframe, robimy to po to, żeby w pętli móc użyć funkcji merge(), która potrzebuje dwóch Dataframe do działania. W 9 linijce pod zmienną df podstawiamy kolejne pliki. W 10 linijce do Dataframe dfJK dołączamy funkcją merge() każdy z pięciu pozostałych plików. Zobaczmy efekt:
======================== RESTART: F:\python38\wpis 17.py =======================
Trzygram JK Bankructwo malego Dzeka JK Dzieci ulicy JK Dziecko salonu JK Kajtus Czarodziej JK Kiedy znow bede maly JK Krol Macius na wyspie bezludnej
0 pani powiedziała że 11.0 NaN NaN NaN NaN NaN
1 że się nie 8.0 NaN NaN NaN NaN NaN
2 żeby się nie 8.0 NaN NaN NaN 8.0 NaN
3 bo nie ma 7.0 NaN NaN NaN NaN NaN
4 z mister taftem 7.0 NaN NaN NaN NaN NaN
5 ale dżek nie 7.0 NaN NaN NaN NaN NaN
6 to znaczy że 7.0 NaN NaN NaN NaN NaN
7 bank dla dzieci 7.0 NaN NaN NaN NaN NaN
8 do mister tafta 7.0 NaN NaN NaN NaN NaN
9 na przyszły rok 7.0 NaN NaN NaN NaN NaN
10 w tej chwili NaN 13.0 NaN NaN 8.0 NaN
11 ja wiem że NaN 8.0 NaN NaN NaN NaN
12 po raz pierwszy NaN 8.0 NaN NaN NaN NaN
13 się z nim NaN 7.0 NaN NaN NaN NaN
14 co to za NaN 7.0 NaN 9.0 NaN 10.0
15 nic więcej nie NaN 7.0 NaN NaN NaN NaN
16 jak gdyby nie NaN 7.0 NaN NaN NaN NaN
17 zdaje mi się NaN 6.0 NaN NaN NaN NaN
18 niech pan kupi NaN 6.0 NaN NaN NaN NaN
19 w stronę wisły NaN 6.0 NaN NaN NaN NaN
20 co to jest NaN NaN 17.0 NaN NaN NaN
21 ja nie chcę NaN NaN 13.0 NaN NaN NaN
22 od izby do NaN NaN 9.0 NaN NaN NaN
23 idę od izby NaN NaN 9.0 NaN NaN NaN
24 izby do izby NaN NaN 9.0 NaN NaN NaN
25 mi się że NaN NaN 8.0 NaN NaN NaN
26 ciastkami na guziku NaN NaN 8.0 NaN NaN NaN
27 z ciastkami na NaN NaN 8.0 NaN NaN NaN
28 rozumie się że NaN NaN 7.0 NaN NaN NaN
29 ha ha ha NaN NaN 6.0 NaN NaN NaN
30 nie wie co NaN NaN NaN 9.0 NaN NaN
31 mu się nie NaN NaN NaN 8.0 NaN NaN
32 że nie ma NaN NaN NaN 7.0 NaN NaN
33 co się stało NaN NaN NaN 7.0 NaN NaN
34 zdaje się że NaN NaN NaN 6.0 NaN NaN
35 oparł się o NaN NaN NaN 5.0 NaN NaN
36 nie bój się NaN NaN NaN 5.0 NaN NaN
37 pyta się mama NaN NaN NaN 5.0 NaN NaN
38 dziwi się kajtuś NaN NaN NaN 5.0 NaN NaN
39 nie wiem czy NaN NaN NaN NaN 18.0 NaN
40 nie wiem co NaN NaN NaN NaN 13.0 NaN
41 się zdaje że NaN NaN NaN NaN 12.0 NaN
42 sam nie wiem NaN NaN NaN NaN 11.0 NaN
43 a ja się NaN NaN NaN NaN 10.0 NaN
44 kiedy byłem dorosły NaN NaN NaN NaN 10.0 NaN
45 a on się NaN NaN NaN NaN 9.0 NaN
46 i nic nie NaN NaN NaN NaN 8.0 8.0
47 wasza królewska mość NaN NaN NaN NaN NaN 27.0
48 waszej królewskiej mości NaN NaN NaN NaN NaN 18.0
49 na bezludną wyspę NaN NaN NaN NaN NaN 18.0
50 na bezludnej wyspie NaN NaN NaN NaN NaN 16.0
51 nie wie maciuś NaN NaN NaN NaN NaN 10.0
52 pyta się maciuś NaN NaN NaN NaN NaN 10.0
>>> Zobaczmy, jak nasze dane wyglądają na wykresie, kod programu zmieni się nieznacznie:
from os import listdir
import pandas as pd
import matplotlib.pyplot as plt
pd.set_option("display.max_columns", 7, "display.width", 200)
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
dfJK = pd.read_pickle\
("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(10)
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(10)
dfJK = pd.merge(dfJK, df, on = "Trzygram", how = "outer")
dfJK.set_index("Trzygram", inplace = True)
dfJK.plot(kind = "barh").invert_yaxis()
plt.show()
W 3 linijce dodaliśmy bibliotekę pyplot. W linijkach 16-18 tworzymy wykres. Zauważ, że nie podajemy kolumn, które mają się znaleźć na wykresie, chcemy je wszystkie. Efekt jest taki:
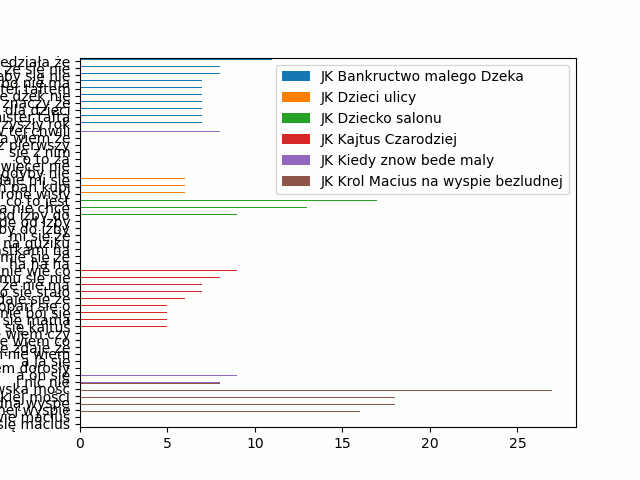
Za dużo i za ciasno, prawda? Ponieważ szukamy tylko powtarzających się 3-gramów, usuńmy z naszego Dataframe wszystkie te, które występują raz. Wykorzystamy do tego metodę .dropna(). Ta metoda usuwa wiersze w których pojawia się komórka bez danych (NaN). Jeśli ją zastosujemy ot tak, bez podawania dodatkowych argumentów:
from os import listdir
import pandas as pd
import matplotlib.pyplot as plt
pd.set_option("display.max_columns", 7, "display.width", 200)
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
dfJK = pd.read_pickle\
("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(10)
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(10)
dfJK = pd.merge(dfJK, df, on = "Trzygram", how = "outer")
dfJK = dfJK.dropna()
print(dfJK)
To otrzymamy taki efekt:
================================================================================== RESTART: F:\python38\wpis 17.py =================================================================================
Empty DataFrame
Columns: [Trzygram, JK Bankructwo malego Dzeka, JK Dzieci ulicy, JK Dziecko salonu, JK Kajtus Czarodziej, JK Kiedy znow bede maly, JK Krol Macius na wyspie bezludnej]
Index: []
>>> W naszym Dataframe, w każdym wierszu znajduje się pusta komórka (NaN) więc wszystkie wiersze zostały usunięte, zostały jedynie nagłówki kolumn. Użyjemy argumentu thresh określającego dopuszczalną liczbę NaN w wierszu, powyżej której dane są usuwane. Popatrzmy na przykład:
from os import listdir
import pandas as pd
import matplotlib.pyplot as plt
pd.set_option("display.max_columns", 7, "display.width", 200)
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
dfJK = pd.read_pickle\
("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(10)
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(10)
dfJK = pd.merge(dfJK, df, on = "Trzygram", how = "outer")
dfJK = dfJK.dropna(thresh = 3)
print(dfJK)
W 16 linijce ustawiamy parametr thresh na równy 3, czyli zostawiamy wiersze, w których NaN występuje 4, 3, 2 , 1 lub 0 razy. Zobaczmy efekt:
======================== RESTART: F:\python38\wpis 17.py =======================
Trzygram JK Bankructwo malego Dzeka JK Dzieci ulicy JK Dziecko salonu JK Kajtus Czarodziej JK Kiedy znow bede maly JK Krol Macius na wyspie bezludnej
2 żeby się nie 8.0 NaN NaN NaN 8.0 NaN
10 w tej chwili NaN 13.0 NaN NaN 8.0 NaN
14 co to za NaN 7.0 NaN 9.0 NaN 10.0
46 i nic nie NaN NaN NaN NaN 8.0 8.0
>>> Mamy niewiele takich 3-gramów. Spróbujmy poszukać w top 15:
from os import listdir
import pandas as pd
import matplotlib.pyplot as plt
pd.set_option("display.max_columns", 7, "display.width", 200)
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
dfJK = pd.read_pickle\
("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(15)
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(15)
dfJK = pd.merge(dfJK, df, on = "Trzygram", how = "outer")
dfJK = dfJK.dropna(thresh = 3)
print(dfJK)
I zobaczmy efekt:
=================================================================== RESTART: F:\python38\wpis 17.py ==================================================================
Trzygram JK Bankructwo malego Dzeka JK Dzieci ulicy JK Dziecko salonu JK Kajtus Czarodziej JK Kiedy znow bede maly JK Krol Macius na wyspie bezludnej
1 że się nie 8.0 NaN NaN NaN 7.0 NaN
2 żeby się nie 8.0 NaN NaN NaN 8.0 NaN
10 się że nie 6.0 NaN 5.0 NaN NaN NaN
14 się zdaje że 6.0 NaN NaN NaN 12.0 NaN
15 w tej chwili NaN 13.0 NaN NaN 8.0 NaN
19 co to za NaN 7.0 NaN 9.0 NaN 10.0
35 mi się że NaN NaN 8.0 NaN 7.0 NaN
64 i nic nie NaN NaN NaN NaN 8.0 8.0
>>> I ten efekt nanieśmy na wykres:
from os import listdir
import pandas as pd
import matplotlib.pyplot as plt
pd.set_option("display.max_columns", 7, "display.width", 200)
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
dfJK = pd.read_pickle\
("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(15)
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(15)
dfJK = pd.merge(dfJK, df, on = "Trzygram", how = "outer")
dfJK = dfJK.dropna(thresh = 3)
dfJK.set_index("Trzygram", inplace = True)
dfJK.plot(kind = "barh").invert_yaxis()
plt.show()
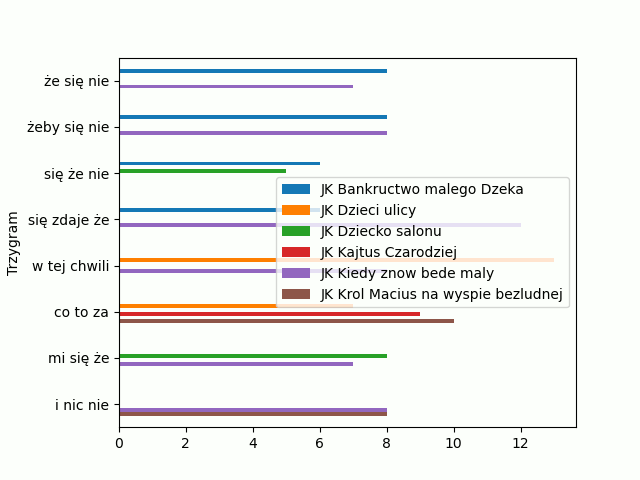
Wykres jest spoko, ale legenda w zupełnie niedobrym miejscu. Do ustawienia legendy w odpowiednim miejscu musimy użyć funkcji legend() z odpowiednimi parametrami. Do umiejscowania legendy w prawym, górnym rogu trzeba użyć argumentu loc = 1. Zobaczmy przykład kodu:
from os import listdir
import pandas as pd
import matplotlib.pyplot as plt
pd.set_option("display.max_columns", 7, "display.width", 200)
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
dfJK = pd.read_pickle\
("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(15)
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(15)
dfJK = pd.merge(dfJK, df, on = "Trzygram", how = "outer")
dfJK = dfJK.dropna(thresh = 3)
dfJK.set_index("Trzygram", inplace = True)
dfJK.plot(kind = "barh").invert_yaxis()
plt.legend(loc = 1)
plt.show()
W 19 linijce podaliśmy odpowiedni argument w funkcji legend(). Zobaczmy efekt:
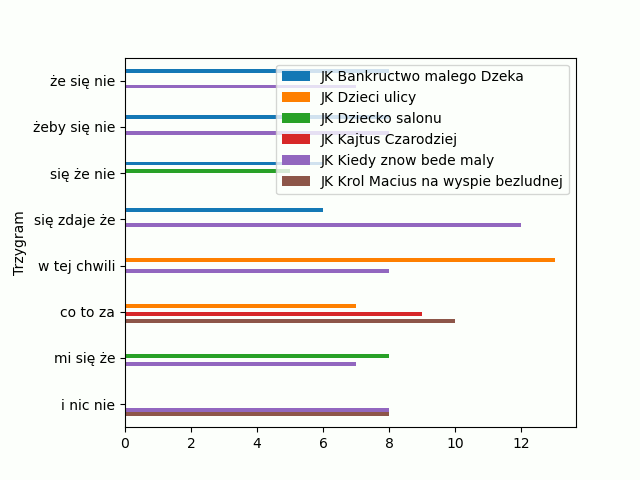
Trochę lepiej, ale my chcemy, żeby legenda znalazła się poza polem kreślenia wykresu, poza czarnym kwadratem słupków. By to osiągnąć potrzebujemy użyć innego argumentu – bbox_to_anchor, który pozwala na ręczne ustawienie legendy w dowolnym miejscu wykresu. Chcąc ustawić legendę w prawym, górnym rogu musimy podać to miejsce. Wykres zaczyna się w punkcie 0, 0 czyli w lewym dolnym rogu, prawy górny róg to wartości 1,1. Popatrz na kod, dla funkcji legend() podamy argument bbox_to_anchor = (1, 1).
from os import listdir
import pandas as pd
import matplotlib.pyplot as plt
pd.set_option("display.max_columns", 7, "display.width", 200)
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
dfJK = pd.read_pickle\
("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(15)
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(15)
dfJK = pd.merge(dfJK, df, on = "Trzygram", how = "outer")
dfJK = dfJK.dropna(thresh = 3)
dfJK.set_index("Trzygram", inplace = True)
dfJK.plot(kind = "barh").invert_yaxis()
plt.legend(bbox_to_anchor = (1, 1))
plt.show()
I zobaczmy efekt:
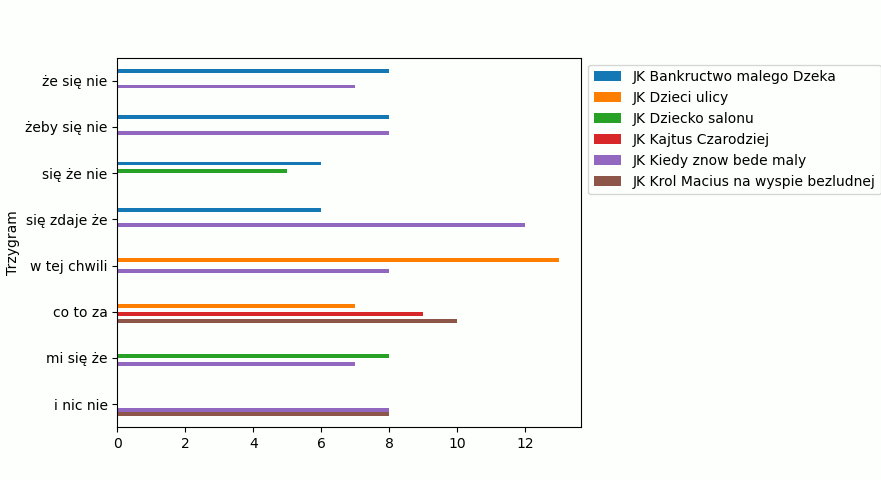
Fantastycznie! To już prawie koniec. W następnej części zajmiemy się zrobieniem wykresów dla obu pisarzy.
Zadanie domowe
Podążanie za instrukcjami, nawet jeśli je wszystkie wykonujesz samodzielnie, nie zrobi z ciebie programisty. Zadania domowe mogą wydawać się na początku trudne. Tu nie ma rozwiązania podanego na talerzu, użyj dowolnych źródeł, by znaleźć odpowiedź.
- Narysuj wykres z legendą, która nie jest otoczona ramką i jest wyświetlana w dwóch kolumnach po trzy wiersze (a nie w jednej kolumnie z 6 wierszami).
- Użyj odpowiedniej funkcji by wartości NaN zastąpić zerami.