
Mamy już nasze dane przygotowane w przyjaznej formie i formacie (pickle). Ostatnim krokiem jest przedstawienie ich na wykresie. Do tworzenia wykresów użyjemy pyplot będącego częścią biblioteki matplotlib. Jeśli nie masz zainstalowanej biblioteki matplotlib, uruchom linię komend (klikając lupę koło znaczka Windows w lewym dolnym rogu, wpisując cmd i klikając enter) i wydaj polecenie pip install matplotlib, jeśli coś nie działa zapoznaj się z tą instrukcją. Spróbujmy narysować najprostszy wykres wykorzystując nasze dane z jednego Dataframe:
import pandas as pd
import matplotlib.pyplot as plt
plik = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
df = pd.read_pickle(plik)
df = df.head(10)
print(df)
df["JK Kiedy znow bede maly"].plot()
W 2 linicje importujemy bibliotekę pyplot, którą dla ułatwienia nazywamy plt, tak samo zrobiliśmy z biblioteką pandas nazywając ją pd. W 9 linijce wybieramy, którą kolumnę Datafrme chcemy przedstawić na wykresie, robimy to w kwadratowych nawiasach, na wybranych danych używamy metody .plot() by wykres narysować. Zobaczmy efekt:
======================== RESTART: F:/python38/wpis 16.py =======================
Trzygram JK Kiedy znow bede maly
606 nie wiem czy 18
3759 nie wiem co 13
6044 się zdaje że 12
1009 sam nie wiem 11
696 a ja się 10
6188 kiedy byłem dorosły 10
4931 a on się 9
1036 żeby się nie 8
13406 i nic nie 8
3231 w tej chwili 8
>>>
Jak widać, nie widać. Python zgodnie z naszym żądaniem wykres narysował, ale go nie pokazał, musimy wydać jeszcze polecenie plt.show()by zobaczyć wykres. Poprawmy program i przy okazji wyrzućmy polecenie drukowania Dataframe:
import pandas as pd
import matplotlib.pyplot as plt
plik = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
df = pd.read_pickle(plik)
df = df.head(10)
df["JK Kiedy znow bede maly"].plot()
plt.show()
Teraz w 9 linijce wydajemy polecenie, by wcześniej przygotowany wykres pokazać. Zobaczmy efekt:
Niewątpliwie wykres jest, ale efekt niczego nie urywa. Wykres musimy dopracować, by stał się zrozumiały dla kogokolwiek. W metodzie .plot() możemy podawać argumenty, użyjmy argumentu type o wartości bar plot(kind = "bar")to zamieni nasz liniowy wykres w słupkowy:
import pandas as pd
import matplotlib.pyplot as plt
plik = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
df = pd.read_pickle(plik)
df = df.head(10)
df["JK Kiedy znow bede maly"].plot(kind = "bar")
plt.show()
Sprawdźmy efekt:
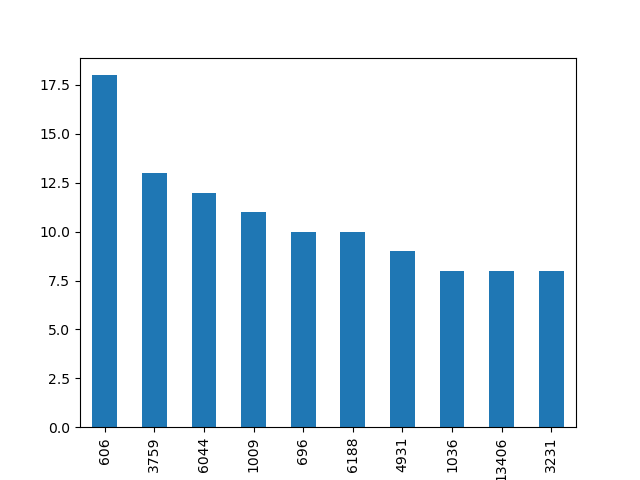
Teraz możemy spróbować przeanalizować co widać na wykresie. Na osi x są indeksy, na osi y wartości z kolumny JK Kiedy znow bede maly. My chcemy żeby na osi x znalazły się 3-gramy. Żeby tak się stało, naszym indeksem musi stać się kolumna nazwana Trzygram, do tego jest potrzeba funkcja set_index(), której argumentem jest nazwa kolumny ustawianej jako indeks. Wypróbujmy taki program:
import pandas as pd
import matplotlib.pyplot as plt
plik = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
df = pd.read_pickle(plik)
df = df.head(10)
print(df)
df.set_index("Trzygram")
print(df)
W 7 linijce drukujemy zaimportowany z pickle Dataframe. W 8 linijce ustawiamy jako indeks kolumnę Trzygram. W 9 linijce drukujemy rezultat zmiany indeksu. Zobaczmy:
======================== RESTART: F:\python38\wpis 16.py =======================
Trzygram JK Kiedy znow bede maly
606 nie wiem czy 18
3759 nie wiem co 13
6044 się zdaje że 12
1009 sam nie wiem 11
696 a ja się 10
6188 kiedy byłem dorosły 10
4931 a on się 9
1036 żeby się nie 8
13406 i nic nie 8
3231 w tej chwili 8
Trzygram JK Kiedy znow bede maly
606 nie wiem czy 18
3759 nie wiem co 13
6044 się zdaje że 12
1009 sam nie wiem 11
696 a ja się 10
6188 kiedy byłem dorosły 10
4931 a on się 9
1036 żeby się nie 8
13406 i nic nie 8
3231 w tej chwili 8
>>>
Nie bardzo widać, by coś się zmieniło. Przeróbmy nieco kod:
import pandas as pd
import matplotlib.pyplot as plt
plik = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
df = pd.read_pickle(plik)
df = df.head(10)
print(df)
print(df.set_index("Trzygram"))
print(df)
Tym razem w 8 linijce naszą zmianę indeksu zamknęliśmy w funkcji print(). W 9 linijce drukujemy jeszcze raz Dataframe. Zobaczmy efekt:
======================== RESTART: F:\python38\wpis 16.py =======================
Trzygram JK Kiedy znow bede maly
606 nie wiem czy 18
3759 nie wiem co 13
6044 się zdaje że 12
1009 sam nie wiem 11
696 a ja się 10
6188 kiedy byłem dorosły 10
4931 a on się 9
1036 żeby się nie 8
13406 i nic nie 8
3231 w tej chwili 8
JK Kiedy znow bede maly
Trzygram
nie wiem czy 18
nie wiem co 13
się zdaje że 12
sam nie wiem 11
a ja się 10
kiedy byłem dorosły 10
a on się 9
żeby się nie 8
i nic nie 8
w tej chwili 8
Trzygram JK Kiedy znow bede maly
606 nie wiem czy 18
3759 nie wiem co 13
6044 się zdaje że 12
1009 sam nie wiem 11
696 a ja się 10
6188 kiedy byłem dorosły 10
4931 a on się 9
1036 żeby się nie 8
13406 i nic nie 8
3231 w tej chwili 8
>>>
Teraz zmiana w drugim wydrukowanym Dataframe jest znaczna! Przeanalizujmy, co się wydarzyło. Użycie print(df.set_index("Trzygram")) zmieniło zauważalnie wygląd danych w Dataframe. Po pierwsze zniknęła kolumna z indeksem, po drugie tytuł pierwszej kolumny, czyli słowo Trzygram jest linijkę niżej niż tytuł 2 kolumny. Jak widzicie zmiana indeksu prowadzi do usunięcia poprzedniego indeksu oraz nazwa kolumny będącej indeksem jest wyróżniona obniżeniem jej. Pozwala to na pierwszy rzut oka stwierdzić, co jest indeksem w wyświetlonym Dataframe. Ale to nie koniec, wydrukowanie Dataframe jeszcze raz (trzeci Dataframe) przywraca jego kształt sprzed zmiany indeksu. To nie jest złośliwość Pythona, ale zapobiegliwość. Z zasady dane źródłowe nie powinny być modyfikowane. Jeśli chcesz zmienić dane, to musisz napisać wprost, że chcesz to zrobić. Możemy taką zmianę zrobić na dwa sposoby. Popatrz na poniższy program:
import pandas as pd
import matplotlib.pyplot as plt
plik = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
df = pd.read_pickle(plik)
df = df.head(10)
print(df)
df1 = df.set_index("Trzygram")
print(df1)
df.set_index("Trzygram", inplace = True)
print(df)
Pierwszy sposób, bardziej bezpieczny jest w 8 linijce, gdzie pod nową zmienną df1 podstawiamy Dataframe z ustawionym nowym indeksem. Drugi sposób, to dodanie do funkcji set_index() argumentu inplace = True, oznacza to, że zmianę chcemy zrobić „w tym miejscu”, czyli nadpisać poprzednie dane. Zobaczmy efekt:
======================== RESTART: F:\python38\wpis 16.py =======================
Trzygram JK Kiedy znow bede maly
606 nie wiem czy 18
3759 nie wiem co 13
6044 się zdaje że 12
1009 sam nie wiem 11
696 a ja się 10
6188 kiedy byłem dorosły 10
4931 a on się 9
1036 żeby się nie 8
13406 i nic nie 8
3231 w tej chwili 8
JK Kiedy znow bede maly
Trzygram
nie wiem czy 18
nie wiem co 13
się zdaje że 12
sam nie wiem 11
a ja się 10
kiedy byłem dorosły 10
a on się 9
żeby się nie 8
i nic nie 8
w tej chwili 8
JK Kiedy znow bede maly
Trzygram
nie wiem czy 18
nie wiem co 13
się zdaje że 12
sam nie wiem 11
a ja się 10
kiedy byłem dorosły 10
a on się 9
żeby się nie 8
i nic nie 8
w tej chwili 8
>>> Metodę wybierz w zależności od potrzeb. Warto zapamiętać, że argument inplace = True jest wykorzystywany w wielu funkcjach bilbioteki Pandas. Poprawmy program rysujący wykres:
import pandas as pd
import matplotlib.pyplot as plt
plik = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
df = pd.read_pickle(plik)
df = df.head(10)
df.set_index("Trzygram", inplace = True)
df["JK Kiedy znow bede maly"].plot(kind = "bar")
plt.show()
Jedyna zmiana jest w 7 linijce, gdzie ustalamy która kolumna jest indeksem. Zobaczmy efekt:
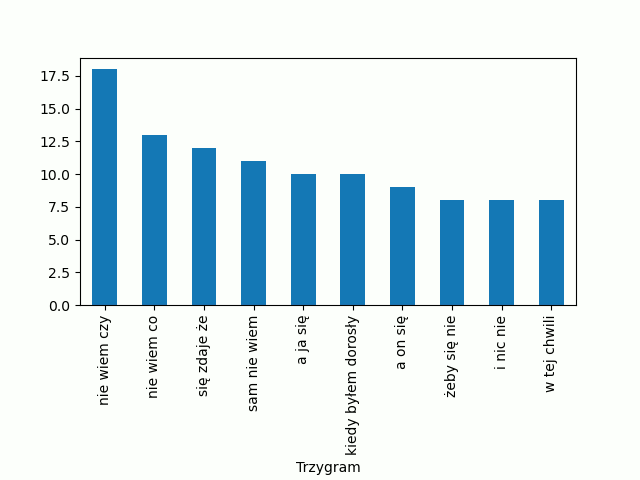
Kolejna korzystna zmiana. Na osi x mamy teraz 3-gramy, oś x jest zatytułowana nazwą kolumny będącej indeksem, a na osi y mamy częstość występowania danego 3-gramu. Jak widać z wykresu najczęściej powtarza się „nie wiem czy”. Jeśli wasz wykres „zjadł” niektóre informacje, użyj ikonki ![]() znajdującej się pod wykresem, by zmienić ustawienia wyświetlania.
znajdującej się pod wykresem, by zmienić ustawienia wyświetlania.
Dla mnie odczytywanie 3-gramów nie jest wygodne, trzeba przechylić głowę w lewo, zmieńmy wykres na poziome słupki, wystarczy zmienić kind na barh:
import pandas as pd
import matplotlib.pyplot as plt
plik = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
df = pd.read_pickle(plik)
df = df.head(10)
df.set_index("Trzygram", inplace = True)
df["JK Kiedy znow bede maly"].plot(kind = "barh")
plt.show()
Zmianę wprowadziłem w 9 linijce kodu. Zobaczmy efekt:
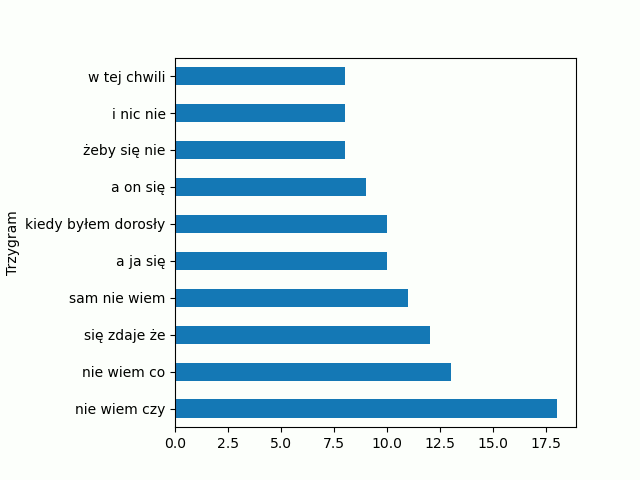
Czytelność się poprawiła, ale zmieniła się kolejność. My chcemy żeby największa wartość była na samej górze. Do tego celu użyjemy metody .invert_yaxis(). Popatrz ja można to zrobić:
import pandas as pd
import matplotlib.pyplot as plt
plik = "F:\\python\\pickle\\JK Kiedy znow bede maly.pkl"
df = pd.read_pickle(plik)
df = df.head(10)
df.set_index("Trzygram", inplace = True)
df["JK Kiedy znow bede maly"].plot(kind = "barh").invert_yaxis()
plt.show()
Przyjrzyj się 9 linijce. Zastosowaliśmy tutaj dwie metody pod rząd (w jednej linijce) dla naszego Dataframe, najpierw metodę .plot() i zaraz po niej .invert_yaxis(). Tak, można tak zrobić i warto używać takiego sposobu nie tylko przy okazji Dataframe. Zobaczmy efekt:
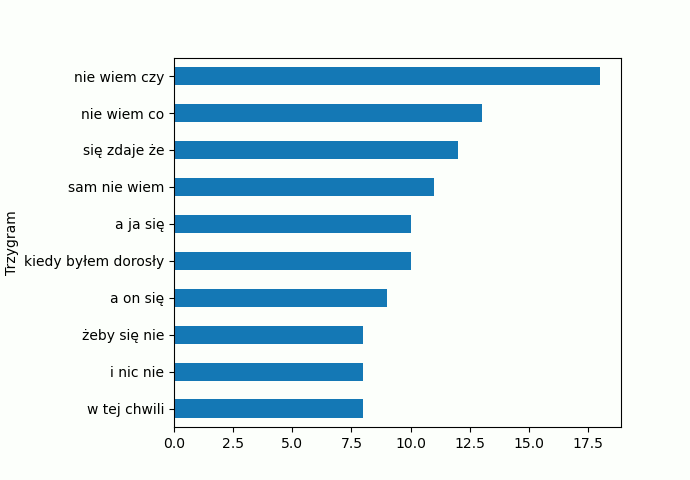
Tyle wystarczy na dzisiaj, w następnej części zajmiemy się kreśleniem na jednym wykresie większej liczby kolumn.
Zadanie domowe
Podążanie za instrukcjami, nawet jeśli je wszystkie wykonujesz samodzielnie, nie zrobi z ciebie programisty. Zadania domowe mogą wydawać się na początku trudne. Tu nie ma rozwiązania podanego na talerzu, użyj dowolnych źródeł, by znaleźć odpowiedź.
- Zmień kolor słupków na zielony, dodaj czarną ramkę do każdego słupka. Zmień wykres na kołowy.
- Przygotuj wykres typu box, przeanalizuj dokładnie co pokazuje. Użyj metody
.describe()na Dataframe, porównaj dane z wykresem box.