
Jak do tej pory udało nam się przedstawić na wykresie powtarzające się 3-gramy dla jednego autora – Janusza Korczaka. Dodajmy do tego drugiego autora Tadeusza Dołęgę-Mostowicza. Popatrz na kod:
from os import listdir
import pandas as pd
import matplotlib.pyplot as plt
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
#wczytaj pierwszy Dataframe z trzygramami Janusza Korczaka
dfJK = pd.read_pickle\
("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(15)
#wczytaj pierwszy Dataframe z trzygramami Tadeusza Dołęgi-Mostowicza
dfTDM = pd.read_pickle\
("F:\\python\\pickle\\TDM Bracia Dalcz i S-ka.pkl").head(15)
#złącz wszystkie Dataframe danego autora w jeden,
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(15)
dfJK = pd.merge(dfJK, df, on = "Trzygram", how = "outer")
elif plik.startswith("TDM") == True and plik.endswith("-ka.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(15)
dfTDM = pd.merge(dfTDM, df, on = "Trzygram", how = "outer")
#usuń trzygramy występujące tylko w jednej książce
dfJK = dfJK.dropna(thresh = 3)
dfJK.set_index("Trzygram", inplace = True)
#wyświetl wartości w poziomych słupkach malejąco
dfJK.plot(kind = "barh").invert_yaxis()
#ustaw legendę wykresu w prawym, górnym rogu
plt.legend(bbox_to_anchor = (1, 1))
plt.show()
#usuń trzygramy występujące tylko w jednej książce
dfTDM = dfTDM.dropna(thresh = 3)
dfTDM.set_index("Trzygram", inplace = True)
dfTDM.plot(kind = "barh").invert_yaxis()
plt.legend(bbox_to_anchor = (1, 1))
plt.show()
W 20 linijce zaczyna się pętla łącząca Dataframe’y drugiego autora. W linijkach 34-38 podajemy sposób wyświetla wykresu dla drugiego autora. Zobaczmy efekt:
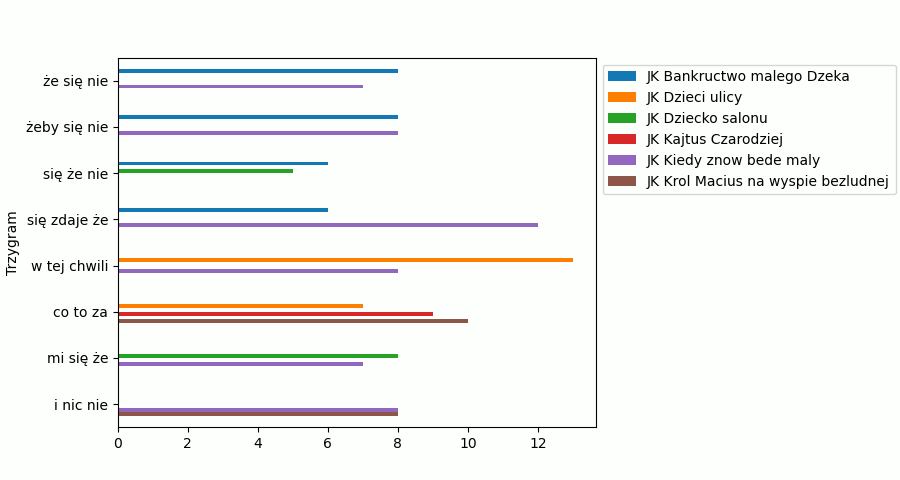
Dwie rzeczy powinniśmy poprawić.
- Pewnie jak zauważyłeś drugi wykres pojawia się dopiero po zamknięciu pierwszego.
- Po drugie, na drugim wykresie mamy całkiem dużo 3-gramów powtarzających się w dwóch i więcej książkach.
Zmieńmy nieco program:
from os import listdir
import pandas as pd
import matplotlib.pyplot as plt
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
#wczytaj pierwszy Dataframe z trzygramami Janusza Korczaka
dfJK = pd.read_pickle\
("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(15)
#wczytaj pierwszy Dataframe z trzygramami Tadeusza Dołęgi-Mostowicza
dfTDM = pd.read_pickle\
("F:\\python\\pickle\\TDM Bracia Dalcz i S-ka.pkl").head(15)
#złącz wszystkie Dataframe danego autora w jeden,
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(15)
dfJK = pd.merge(dfJK, df, on = "Trzygram", how = "outer")
elif plik.startswith("TDM") == True and plik.endswith("-ka.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(15)
dfTDM = pd.merge(dfTDM, df, on = "Trzygram", how = "outer")
#usuń trzygramy występujące tylko w jednej książce
dfJK = dfJK.dropna(thresh = 3)
dfJK.set_index("Trzygram", inplace = True)
#wyświetl wartości w poziomych słupkach malejąco
dfJK.plot(kind = "barh").invert_yaxis()
#ustaw legendę wykresu w prawym, górnym rogu
plt.legend(bbox_to_anchor = (1, 1))
#usuń trzygramy występujące w mniej niż trzech książkach
dfTDM = dfTDM.dropna(thresh = 4)
dfTDM.set_index("Trzygram", inplace = True)
dfTDM.plot(kind = "barh").invert_yaxis()
plt.legend(bbox_to_anchor = (1, 1))
#narysuj wykres
plt.show()
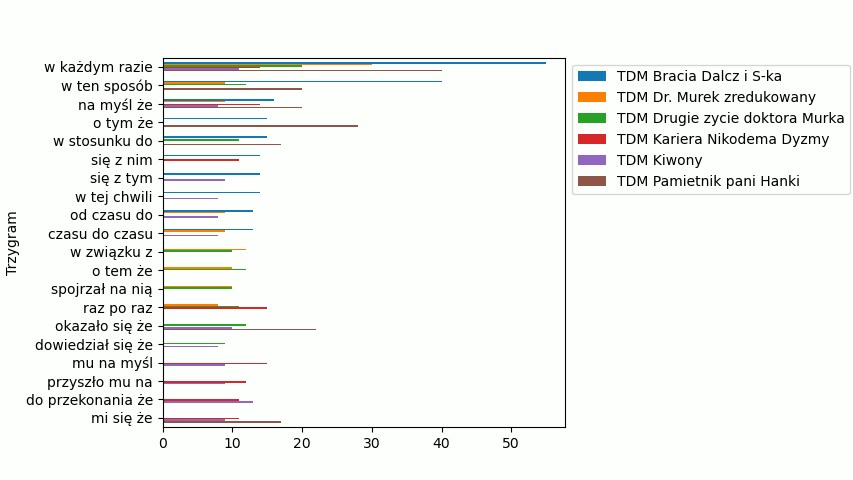
W 33 linijce zmieniliśmy wartość parametru thresh dla powieści Tadeusza Dołęgi-Mostowicza. A funkcja show() występuje tylko raz w ostatniej linijce. Zobaczmy jak teraz wygląda drugi wykres:
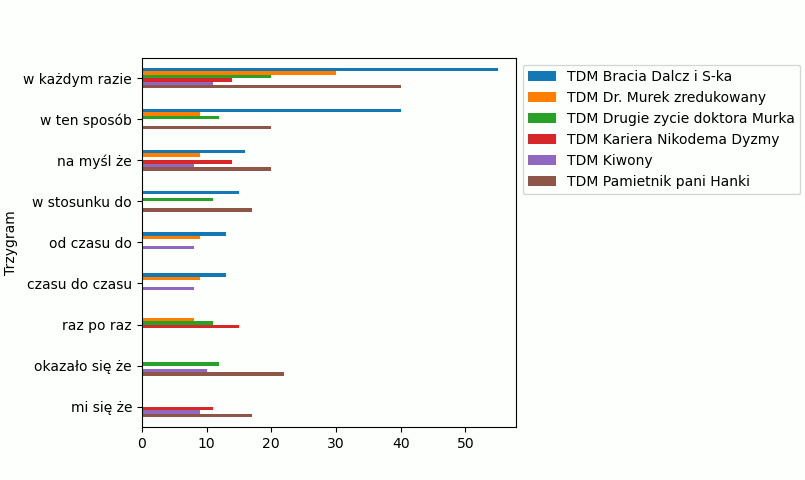
Teraz mamy mniej 3-gramów, ale każdy z nich występuje w co najmniej połowie powieści. Nad wykresami sobie jeszcze trochę popracujmy, niech będą ładniejsze. Teraz pojawiają się nam dwa osobne okna z wykresem, lepiej jeśli umieścimy oba wykresy w jednym oknie. Musimy do tego użyć funkcji subplots(). Popatrz na przykład:
from os import listdir
import pandas as pd
import matplotlib.pyplot as plt
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
#wczytaj pierwszy Dataframe z trzygramami Janusza Korczaka
dfJK = pd.read_pickle\
("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(15)
#wczytaj pierwszy Dataframe z trzygramami Tadeusza Dołęgi-Mostowicza
dfTDM = pd.read_pickle\
("F:\\python\\pickle\\TDM Bracia Dalcz i S-ka.pkl").head(15)
#złącz wszystkie Dataframe danego autora w jeden,
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(15)
dfJK = pd.merge(dfJK, df, on = "Trzygram", how = "outer")
elif plik.startswith("TDM") == True and plik.endswith("-ka.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(15)
dfTDM = pd.merge(dfTDM, df, on = "Trzygram", how = "outer")
#usuń trzygramy występujące tylko w jednej książce
dfJK = dfJK.dropna(thresh = 3)
dfJK.set_index("Trzygram", inplace = True)
#usuń trzygramy występujące w mniej niż trzech książkach
dfTDM = dfTDM.dropna(thresh = 4)
dfTDM.set_index("Trzygram", inplace = True)
#zdefiniuj wykres składającu się z dwóch podwykresów, jeden pod drugim
wykres, podwykres = plt.subplots(nrows = 2)
#wyświetl wartości w poziomych słupkach malejąco
dfJK.plot(kind = "barh", ax = podwykres[0]).invert_yaxis()
dfTDM.plot(kind = "barh", ax = podwykres[1]).invert_yaxis()
#narysuj wykres
plt.show()
Trochę przeorganizowałem kod, by był czytelniejszy. W 31 linijce definiujemy, że nasz wykres będzie się składał z podwykresów wykres, podwykres = za pomocą funkcji subplots(), której argumentem jest liczba wierszy równa 2 plt.subplots(nrows = 2). W linijkach 33 i 34 do funkcji plot() dodajemy argument ax do którego przyporządkowujemy, który podwykres ma być w pierwszym wierszu (ten z indeksem [0]), a który w drugim (ten z indeksem[1]). Zobaczmy efekt:
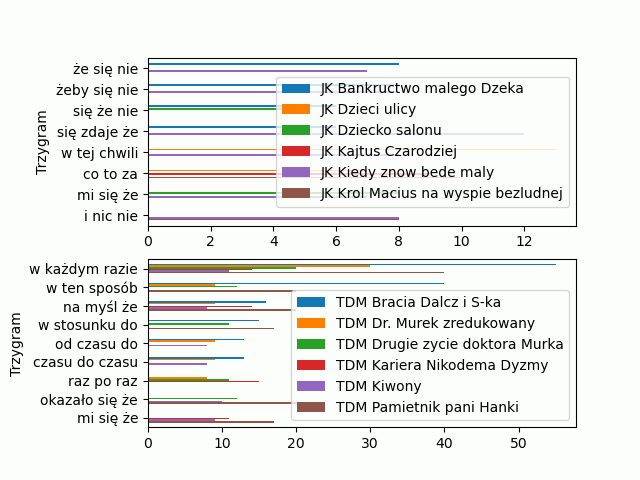
Efekt jest fajny, ale co oznacza taki dziwny zapis wykres, podwykres = plt.subplots(nrows = 2) ? Popatrz na prosty przykład, jaki możesz zrobić w terminalu IDLE:
>>> x, y = 3, 4
>>> x
3
>>> y
4
>>> wykres, podwykres = 3, 4
>>> wykres
3
>>> podwykres
4
>>> W pierwszym przykładzie zamiast pisać w osobnych linijkach
x = 3
y = 4
Zapisaliśmy wszystko w jednej linijce. Oczywiście w kodzie naszego głównego programu wykres i podwykres nie są liczbowym typem danych, sprawdźmy czym są. Uruchom nasz program, a potem sprawdź w terminalu IDLE:
>>> wykres
<Figure size 640x480 with 2 Axes>
>>> podwykres
array([<matplotlib.axes._subplots.AxesSubplot object at 0x09B13208>,
<matplotlib.axes._subplots.AxesSubplot object at 0x09A24448>],
dtype=object)
>>> Teraz widzimy, że wykres to figura o takich a takich rozmiarach, składająca się z dwóch Axes (osi). Podwykres to dwa obiekty zapisane na liście.
Pozostaje ustawić legendę, dla każdego z podwykresów trzeba zrobić to osobno:
from os import listdir
import pandas as pd
import matplotlib.pyplot as plt
sciezka_pickle = "F:\\python\\pickle\\"
pliki_pickle = listdir(sciezka_pickle)
#wczytaj pierwszy Dataframe z trzygramami Janusza Korczaka
dfJK = pd.read_pickle\
("F:\\python\\pickle\\JK Bankructwo malego Dzeka.pkl").head(15)
#wczytaj pierwszy Dataframe z trzygramami Tadeusza Dołęgi-Mostowicza
dfTDM = pd.read_pickle\
("F:\\python\\pickle\\TDM Bracia Dalcz i S-ka.pkl").head(15)
#złącz wszystkie Dataframe danego autora w jeden,
for plik in pliki_pickle:
if plik.startswith("JK") == True and plik.endswith("a.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(15)
dfJK = pd.merge(dfJK, df, on = "Trzygram", how = "outer")
elif plik.startswith("TDM") == True and plik.endswith("-ka.pkl") == False:
df = pd.read_pickle(sciezka_pickle + plik).head(15)
dfTDM = pd.merge(dfTDM, df, on = "Trzygram", how = "outer")
#usuń trzygramy występujące tylko w jednej książce
dfJK = dfJK.dropna(thresh = 3)
dfJK.set_index("Trzygram", inplace = True)
#usuń trzygramy występujące w mniej niż trzech książkach
dfTDM = dfTDM.dropna(thresh = 4)
dfTDM.set_index("Trzygram", inplace = True)
#zdefiniuj wykres składającu się z dwóch podwykresów, jeden pod drugim
wykres, podwykres = plt.subplots(nrows = 2)
#wyświetl wartości w poziomych słupkach malejąco
dfJK.plot(kind = "barh", ax = podwykres[0]).invert_yaxis()
#z legendą poza obszarem kreślenia w prawym, górnym rogu
podwykres[0].legend(bbox_to_anchor = (1, 1))
dfTDM.plot(kind = "barh", ax = podwykres[1]).invert_yaxis()
podwykres[1].legend(bbox_to_anchor = (1, 1))
#narysuj wykres
plt.show()
W linijkach 35 i 37, zamiast plt.legend() musimy odnieść się do poszczególnych podwykresów podwykres[0].legend() i podwykres[1].legend. Zobaczmy ostateczny efekt!
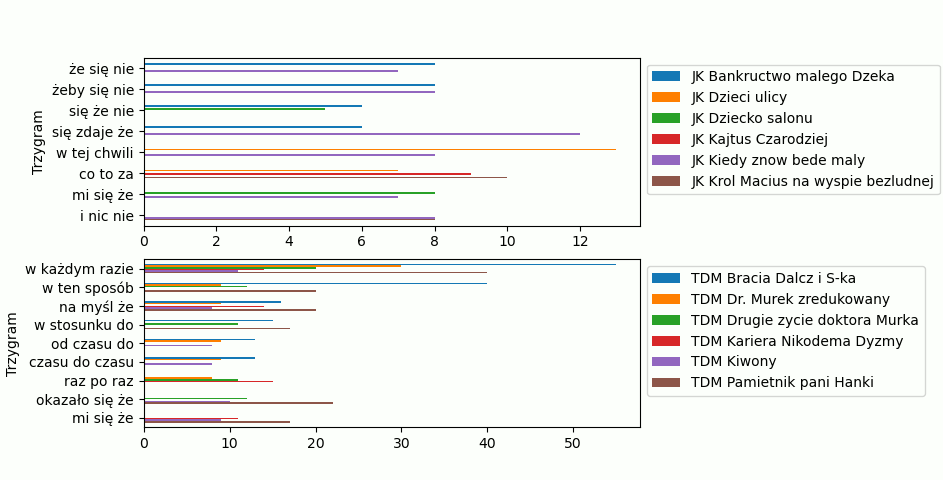
Oczywiście wykresy można jeszcze dopieszczać, zmienić grubość słupków, dodać tytuł wykresu, zmienić wielkość czcionki, itp., itd. To zostawiam już Tobie. Przejdźmy do najważniejszej rzeczy w data science, wyciągnięcia wniosków.
Wnioski
Janusz Korczak:
- Często używa zbitek bardzo do siebie podobnych „że się nie”, „żeby się nie”, „się że nie”, „mi się że”. Popatrz na ostatnie dwie, może tutaj jest częsty 4-gram „mi się że nie”? Zawsze możesz to sprawdzić!
- Najpopularniejsze 3-gramy nie powtarzają się często w różnych książkach, wiele z nich występuje tylko w dwóch (33,33%).
Tadeusz Dołęga-Mostowicz
- Widać, że lubi zwroty „od czasu do czasu” i „raz po raz”.
- Najpopularniejsze 3-gramy występują częściej w różnych książkach (50% i częściej).
Oczywiście wniosków można wyciągnąć dużo więcej, zachęcam was do tego. Popatrz chociażby na częstość występowania 3-gramów u autorów. U Janusza Korczaka rzadko przekraczane jest 10 powtórzeń, u Tadeusza Dołęgi-Mostowicza 20 powtórzeń nie jest rzadkością, może to zależy od „grubości książki” i ilości słów w niej? Może się pokusisz o znormalizowanie wykresów poprzez podzielenie liczby 3-gramów z danej książki przez liczbę słów tej książki? Gdybyście dostali do przeanalizowania kolejną książkę, o której wiedzielibyście, że jest autorstwa jednego z analizowanych pisarzy, moglibyście na podstawie 3-gramów spróbować odgadnąć czyja to powieść.
We wstępie pokazałem wam porównanie dla książek Roberta M. Wegnera i Katarzyny Bondy, jeśli macie dostęp do e-booków możecie sprawdzić jak piszą wasi ulubieni autorzy! A może okaże się, że w jednej z książek styl jest zupełnie inny niż w pozostałych. Czy to świadczy o umiejętnościach autora, a może książkę napisał autor-widmo?
Zakończenie
Jeśli dotrwałeś do końca kursu, gratuluję! Nauczyłeś się naprawdę dużo rzeczy i od razu stosowałeś je w praktyce. Zacząłeś od rozróżnienia tekstowego typu danych od liczbowego, a skończyłeś na prezentacji na wykresie wyników zaawansowanej obróbki tekstu! Czy jesteś programistą? Nie, ale potrafisz programować, analizować i rozwiązywać problemy. Programowanie jest przydatne w wielu zawodach i pozwala zautomatyzować nudne czynności. Życzę powodzenia i zapraszam do innych kursów ze strony https://inferiordatascience.com/.