Każda strona wyświetlana w Twojej przeglądarce składa się z kilku podstawowych elementów. Niektóre z nich są wyświetlane, inne zawierają informacje, których nie widzisz. W zależności od użytej technologii na stronie internetowej znalezienie i pozyskanie danych może być łatwiejsze lub trudniejsze. Zacznijmy od najprostszych przypadków na najprostszych stronach.
Struktura HTML
Otwórz w nowej karcie tę stronę: https://inferiordatascience.com/przyklad.html. Zobacz, nie jest jakoś specjalnie skomplikowana. W tym kursie Pythona mniej nas interesuje jak widać stronę na monitorze, bardziej chcemy widzieć jak wygląda źródło strony. Na otwartej stronie https://inferiordatascience.com/przyklad.html w dowolnym miejscu jej treści kliknij prawym klawiszem myszy i wybierz opcję z menu Źródło strony/Pokaż źródło strony/Wyświetl źródło strony – opcja zależy od przeglądarki jakiej używasz. Na szczęście niezależnie od przeglądarki, źródło strony będzie wyglądać tak samo, czyli tak:
<html>
<head>
<title>The Very Last Page On The Internet</title>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
</head>
<body onUnload="onExit()" bgcolor="#FFFFFF" text="#000000">
<p> </p>
<p> </p>
<table width="90%" border="0" cellspacing="0" cellpadding="0" align="center">
<tr>
<td colspan="2">
<h1 align="center"><font face="Verdana, Arial, Helvetica, sans-serif"><b>This
Is The Very Last Page On The Internet</b></font></h1>
<h1 align="center"> </h1>
<h1 align="center"><b><font face="Verdana, Arial, Helvetica, sans-serif" color="#666666">Please
turn off your computer!!!</font></b></h1>
<h1 align="center"> </h1>
<h1 align="center"><font color="#666666"><b><font face="Verdana, Arial, Helvetica, sans-serif">Go
outside and play!!!</font></b></font></h1>
<h1 align="center"> </h1>
<h1 align="center"><b><font face="Verdana, Arial, Helvetica, sans-serif" color="#FF0000">The
End.</font><font face="Verdana, Arial, Helvetica, sans-serif" color="#666666">
</font></b></h1>
</td>
</tr>
<tr>
<td> </td>
<td> </td>
</tr>
</table>
</body>
</html>
By skutecznie zająć się web scrapingiem, musisz poznać kilka zasad jakimi rządzi się język HTML i jak strony pisane w HTML zazwyczaj wyglądają. Na tej stronie widać te najbardziej podstawowe zasady:
- Znaczniki języka HTML znajdują się w nawiasach ostrokątnych
< >. - Prawie każdemu znacznikowi otwierającemu, np.
<title>odpowiada znacznik zamykający, o tej samej treści, ale z dodanym ukośnikiem „/”, np.</title>. - Wszystko, co znajduje się między
< >ma wpływ na wygląd strony, ale nie jest na stronie wyświetlane. - No i przez analogię, wszystko co znajduje się miedzy
> <jest przez stronę wyświetlane. - Cała strona znajduje się między znacznikami
<HTML>i</HTML>. - Między znacznikami
<HTML>i</HTML>znajduje się nagłówek umieszczany między<head>i</head>. - Między znacznikami
<head>i</head>znajduje się tytuł strony umieszczany między znacznikami<title>i</title>. - Po
</head>ale przed</HTML>znajduje się zawartość strony umieszczona między znacznikami<body>i</body>.
Nas najbardziej będzie interesowała zawartość strony, czyli wszystko co jest między znacznikami <body> i </body>, czyli ciało strony, i to je będziemy próbowali pobrać naszym programem.
Poświęć chwilę, by zapoznać się z podstawami HTML. Wyświetlone źródło strony wklej do notatnika i zapisz pod dowolną nazwą z rozszerzeniem .html:
- Kliknij Plik->Zapisz jako…
- Zmień opcję Zapisz jako typ na Wszystkie pliki
- Nadaj dowolną nazwę i na końcu niej dopisz „.html”
- Kliknij Zapisz
- Nie zamykaj Notatnika

Tak zapisany plik otworzysz w przeglądarce zwykłym, dwukrotnym kliknięciem. Otwórz i nie zamykaj przeglądarki. Popatrzmy jak na wyświetlanie wpłyną zmiany w źródle HTML, które masz w otwartym pliku w Notatniku.
- W drugiej linijce w Notatniku zmień tekst
The Very Last Page On The Internetnainferiordatascience.com - Zapisz plik (ctrl+s)
- Przełącz się do przeglądarki gdzie masz otwartą stronę i popatrz na nazwę karty
- Odśwież stronę (F5)
- Zobacz jak zmienił się tytuł karty.
U mnie zmiana wygląda tak:
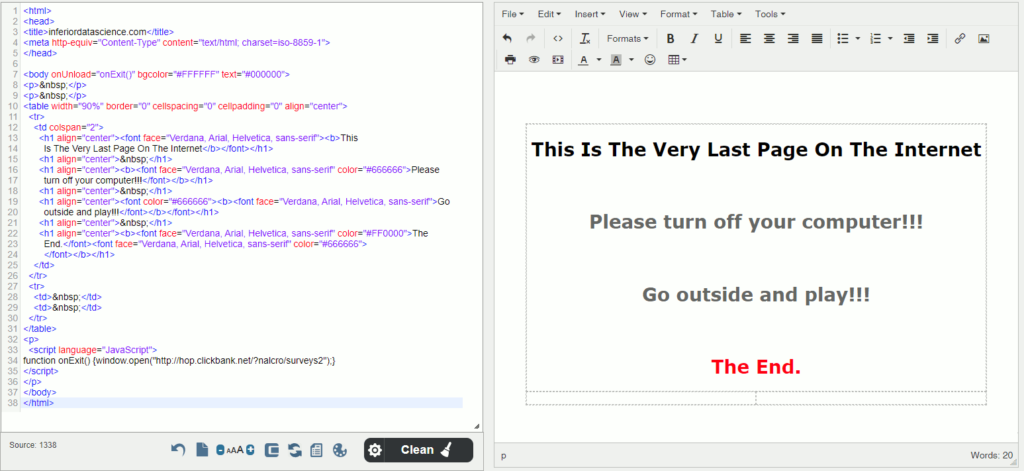
Wprowadzanie innych zmian podejrzymy już sobie w bardziej przyjazny sposób, w edytorze HTML on-line, który znajdziesz na tej stronie. Przeklej źródło strony do lewego okna, po prawej pojawi się treść. U mnie wygląda to tak:
Zacznijmy wprowadzać zmiany. Wszystko, co zmienisz w lewym okienku na bieżąco pojawi się w prawym. Zrób te wszystkie zmiany:
- W 13 linijce zastąp teks
This Is The Very Last Page On The InternettekstemStrona do web scrapingu - W 15 linicjce zastąp kolor
color="#666666"koloremcolor="#666600" - W 18 i 19 linijce wszystkie
h1zastąph4 - Po 23 linijce zrób nową i wpisz w nią:
<p> znacznik "p" pozwala na</p><p> tworzenie nowych paragrafów</p>- Dodaj jeszcze jedną linijkę i wpisz w nią:
<p> a żeby w paragrafie zacząć nową linię<br> użyj znacznika br</p>Efekt tych zmian powinien wyglądać tak:

Jak widzisz, nawet na prostej stronie można wprowadzić wiele zmian formatowania i jak prosto do strony dodaje się nową treść.
Zauważ też, że nas interesuje treść, nie obchodzi cię czy treść jest na czerwono, czy różowo. Natomiast interesuje cię, czy ta treść jest nagłówkiem, np. „h1” albo „h4”, albo czy jest w jednym, czy wielu paragrafach. Za każdym razem, gdy będziesz przygotowywać program do web scrapingu, będziesz musiał zapoznać się ze źródłem strony. Nie przerażaj się tym, nie musisz być ekspertem od HTML, w tym kursie Pythona zobaczysz, że potrzebujesz identyfikować tylko wybrane elementy.
Zadanie domowe
Podążanie za instrukcjami, nawet jeśli je wszystkie wykonujesz samodzielnie, nie zrobi z ciebie programisty. Zadania domowe mogą wydawać się na początku trudne. Tu nie ma rozwiązania podanego na talerzu, użyj dowolnych źródeł, by znaleźć odpowiedź.
- W pliku .html za pomocą notatnika, dodaj link do dowolnej strony, który otworzy się po kliknięciu tekstu
kliknij tutaj - Za pomocą notatnika dodaj do pliku tabelę, której nagłówki będą nazywać się nazwa i cena. Tabela ma mieć jeden wiersz w którym nazwą będzie pralka a ceną 100.