Ostatnio skupiliśmy się na jednej tabeli i zapisaniu do pliku informacji o wszystkich odmianach występujących tylko w tej jednej tabeli. Udało nam się to połowicznie, prócz danych dla 10 odmian mamy też w pliku 10 nagłówków. Pozbyć się ich można na kilka sposobów, przedstawię najpierw te, które mi się nie podobają, albo źle działają:
- Zapisać do pliku nagłówki i dane tylko dla strony https://inferiordatascience.com/odmiana1/ a dla pozostałych jedynie dane – no dobrze, a co jeśli nie każda tabela jest na pierwszej stronie? Wiemy, że tak jest, bo zliczaliśmy niedawno liczbę tabel. Ten pomysł się nie sprawdzi.
- W zapisanym pliku usunąć co drugi wiersz – też nie do końca dobrze, ta sama tabela dla różnych odmian może mieć różną liczbę wierszy.
- Usunąć linijki nagłówka, które występują więcej niż raz – w tym wypadku dla każdej tabeli trzeba zdefiniować co jest nagłówkiem, wyszukać go i skasować. To dość pracochłonne.
To co chcemy zrobić, to zapisać nagłówek przy pierwszym wystąpieniu tabeli i zrobić to tylko raz. Zrobić to niezależnie na której stronie pojawia się po raz pierwszy tabela i niezależnie ile ma wierszy. To może wystarczy sprawdzić, czy plik o nazwie równej id tabeli istnieje? Jeśli nie – zapisz nagłówki i dane; jeśli tak – zapisz tylko dane. Zacznijmy od prostego przykładu. Popatrz na kod:
from os import path
if path.isfile('ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek.csv'):
print("jest taki plik")
else:
print("nie ma takiego pliku")
W 1 linijce z modułu os importujemy path. W path znajdziemy wszystkie funkcje dotyczące katalogów i plików.
W 3 linijce używamy instrukcji warunkowej if z funkcją isfile(), której argumentem jest nazwa poszukiwanego pliku. Jak pewnie się domyślasz funkcja ta sprawdza czy w danym miejscu istnieje dany plik. My nie podajemy ścieżki do pliku, dlatego, że pliki zapisują się w domyślnej lokalizacji i są sprawdzane, czy w domyślnej lokalizacji istnieją. Całą trzecią linijkę można przeczytać tak : Jeśli plik o nazwie ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek.csv istnieje to:.
W 4 linijce drukujemy potwierdzenie, że plik istnieje
W 5 linijce else: oznacza w przeciwnym wypadku:.
W 6 linijce drukujemy potwierdzenie, że pliku nie ma.
Sprawdźmy działanie:
==================== RESTART: F:/python38/Web scraping 09.py ===================
jest taki plik
>>> A gdy plik usunę plik z folderu:
==================== RESTART: F:/python38/Web scraping 09.py ===================
nie ma takiego pliku
>>> No i fajnie! Czyli wiemy co zrobić w naszym głównym programie! Pozostaje tylko dodatkowy warunek umieścić w odpowiednim miejscu naszego programu. Spróbuj zrobić to po swojemu a potem sprawdź mój sposób:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import csv
from os import path
tabela_gatunek = "ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek"
#dla odmian
for nr in range(1, 13):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
#i jeśli id odpowiada zmiennej tabela_gatunek
if tytul_tabeli == tabela_gatunek:
if path.isfile(f"{tabela_gatunek}.csv"):
komorki= [f"odmiana{nr}"]
for indeks in range(1, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
#zapisz listę tabeli do pliku o nazwie = id
with open(f"{tytul_tabeli}.csv", "a", newline = "") as plik:
csv.writer(plik).writerow(komorki)
else:
komorki= [f"id_odmiany"]
#zapisz nagłówki tabeli
for indeks in range(0, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
#zapisz listę tabeli do pliku o nazwie = id
with open(f"{tytul_tabeli}.csv", "a", newline = "") as plik:
csv.writer(plik).writerow(komorki)
komorki= [f"odmiana{nr}"]
#zapisz treść tabeli
for indeks in range(1, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
#zapisz listę tabeli do pliku o nazwie = id
with open(f"{tytul_tabeli}.csv", "a", newline = "") as plik:
csv.writer(plik).writerow(komorki)
#jeśli strony nie ma, poinformuj
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
Zwycięstwo! Działa i zapisuje jak trzeba. Jedyne, co powinno cię niepokoić to pewna rozwlekłość programu i duża liczba wcięć z powodu try:, if:, for:. Program jeszcze jest czytelny, ale jego funkcjonalność i czytelność można poprawić. Do tego celu wprowadzimy własne funkcje. Już za chwileczkę, już za momencik napiszesz swoją pierwszą!
Funkcje
Funkcja nie jest dla Ciebie niczym nowym. Znasz np. funkcję print() i wiesz do czego służy. Za to nie ma w Pythonie funkcji, w której argumentami są dwie liczby a funkcja mówi ile procent pierwszej liczby stanowi druga liczba i ile procent drugiej liczby stanowi pierwsza liczba. Popatrz na przykład, który napiszemy w terminalu:
Python 3.8.2 (tags/v3.8.2:7b3ab59, Feb 25 2020, 22:45:29) [MSC v.1916 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license()" for more information.
>>> 34*100/100
34.0
>>> 100*100/34
294.11764705882354
>>> W pierwszym przykładzie sprawdzamy ile procent liczby 100 stanowi liczba 34, wynikiem jest 34,0 i to zgadza się ze stanem naszej wiedzy. W drugim przykładzie sprawdzamy ile procent liczby 34 stanowi liczba 100, wynikiem jest 294,117647 z hakiem i to się również zgadza. Zmieńmy nasz przykład nieco i użyjmy zamiast liczb zmiennych.
>>> a = 34
>>> b = 100
>>> a*100/b
34.0
>>> b*100/a
294.11764705882354
>>> Jak widać do wyliczenia naszych procentów są potrzebne dwie zmienne. Popatrz teraz na kod, zaraz go przeanalizujemy.
def ile_procent(a, b):
print(a*100/b)
print(b*100/a)
ile_procent(34,100)
W 1 linijce pojawia się słowo kluczowe def, dzięki temu Python wie, że zaczynasz definiować funkcję. Następnie jest nazwa funkcji, nazwa musi spełniać takie same zasady jak nazwa zmiennej. Jak każda funkcja musi mieć nawiasy, ale nie musi mieć argumentów. w naszym wypadku argumenty są potrzebne i będą nimi dwie zmienne. Linijka kończy się dwukropkiem, dwukropek zawsze będzie na końcu zdefiniowanej nazwy funkcji i jej argumentów.
W 2 i 3 linijce, które są wcięte (jak wszystko po dwukropku) piszemy co ma się wydarzyć po wywołaniu funkcji. W naszym wypadku chcemy wydrukować policzone wartości procentów.
W 5 linijce wywołujesz funkcję z argumentami 34 i 100, czyli pod a zostanie podstawione 34 a pod b 100.
==================== RESTART: F:\python38\Web scraping 09.py ===================
34.0
294.11764705882354
>>> Działa, uładnijmy nieco kod:
def ile_procent(a, b):
print(f"liczba {a} stanowi {round(a*100/b,2)} procent liczby {b}")
print(f"liczba {b} stanowi {round(b*100/a,2)} procent liczby {a}")
ile_procent(34,100)
W 3 i 4 linijce dodaliśmy informację precyzującą co oznaczają wyniki. Dodatkowo dodaliśmy funkcję round(), tej funkcji podajemy dwa argumenty: round(liczba, liczba miejsc po przecinku), efektem jest zaokrąglenie liczby do podanej dokładności. Efekt:
==================== RESTART: H:\python39\Scripts\skasuj.py ====================
liczba 34 stanowi 34.0 procent liczby 100
liczba 100 stanowi 294.12 procent liczby 34
>>> Twoje własne funkcje mają masę przydatnych zastosowań, popatrz co fajnego możesz zrobić używając tej prostej funkcji:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def ile_procent(a, b):
print(f"liczba paragrafów strony {strony[0]} to {round(a*100/b,2)} procent "\
f"paragrafów strony {strony[1]}")
print(f"liczba paragrafów strony {strony[1]} to {round(b*100/a,2)} procent "\
f"paragrafów strony {strony[0]}")
strony = ["https://www.python.org/", "https://www.rust-lang.org/"]
for strona in strony:
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
paragraf = html.findAll("p")
if strona == "https://www.python.org/":
strona_a = len(paragraf)
else:
strona_b = len(paragraf)
ile_procent(strona_a,strona_b)
Mimo braku komentarzy na pewno rozumiesz co tu się wydarzyło, a przykładowy efekt jest taki:
=============== RESTART: F:\python38\Web scraping 09.py ==============
liczba paragrafów strony https://www.python.org/ to 115.0 procent paragrafów strony https://www.rust-lang.org/
liczba paragrafów strony https://www.rust-lang.org/ to 86.96 procent paragrafów strony https://www.python.org/
>>> Skoro już wiesz jak definiuje się funkcje i jak się je zapisuje, wprowadźmy jakąś do naszego programu. Przyjrzymy się kawałkowi kodu, który powtarza się w naszym programie aż 3 razy:
with open(f"{tytul_tabeli}.csv", "a", newline = "") as plik:
csv.writer(plik).writerow(komorki)
Mamy trzykrotnie dokładnie te same dwie linijki. Możesz sobie wyobrazić, że będzie ich nawet więcej, bo będziemy zapisywać kolejne tabele i będą się od siebie trochę różnić sposobem organizacji danych (dla niektórych tabel „nagłówki” są w kolumnach, dla innych w wierszach), ale zawsze na koniec trzeba je zapisać. Zdefiniujmy funkcję, która będzie zapisywać dane z list do pliku .csv:
def zapisz_plik():
with open(f"{tytul_tabeli}.csv", "a", newline = "") as plik:
csv.writer(plik).writerow(komorki)
W 1 linijce definiujemy nazwę funkcji, nazwa powinna od razu wyjaśniać co dana funkcja robi, następnie w nawiasie nie podajemy argumentu. Nie ma takiej potrzebny, wszystkie niezbędne informacje i zmienne są już w programie zapisane.
W 2 i 3 linijce jest kod, który już doskonale znasz, odpowiada za zapisanie danych do pliku o nazwie równej id tabeli. Umieśćmy definicję funkcji i jej wywołania w programie:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import csv
from os import path
def zapisz_plik():
with open(f"{tytul_tabeli}.csv", "a", newline = "") as plik:
csv.writer(plik).writerow(komorki)
tabela_gatunek = "ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek"
#dla odmian
for nr in range(1, 13):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
#i jeśli id odpowiada zmiennej tabela_gatunek
if tytul_tabeli == tabela_gatunek:
if path.isfile(f"{tabela_gatunek}.csv"):
komorki= [f"odmiana{nr}"]
for indeks in range(1, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
#zapisz listę tabeli do pliku o nazwie = id
zapisz_plik()
else:
komorki= [f"id_odmiany"]
#zapisz nagłówki tabeli
for indeks in range(0, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
#zapisz listę tabeli do pliku o nazwie = id
zapisz_plik()
komorki= [f"odmiana{nr}"]
#zapisz treść tabeli
for indeks in range(1, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
#zapisz listę tabeli do pliku o nazwie = id
zapisz_plik()
#jeśli strony nie ma, poinformuj
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
W linijkach 7-9 zdefiniowałeś funkcję. Funkcje definiuje się na początku programu.
W linijkach 34, 42, 49 funkcja jest wywoływana i robi co powinna robić, sprawdź to sam!
Skoro nam tak dobrze poszło, to może zdefiniujmy funkcję zapisującą nagłówki pierwszej tabeli „gatunek” do listy? Zrobimy to w ten sam sposób, co definiowane funkcji zapisującej dane do pliku. Zaproponuj funkcję a potem sprawdź czy wygląda podobnie do mojej. Jeśli nawet wygląda inaczej a działa, to dobra robota!
def zapisz_naglowek():
for indeks in range(0, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
W 1 linijce mamy nazwę funkcji, tym razem też nie będą potrzebne argumenty.
W linijkach 2-4 zapisana jest pętla, która wybiera te komórki tabeli, zawierające nagłówki i zapisuje je na liście.
Dodajmy tę funkcję do naszego programu:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import csv
from os import path
def zapisz_naglowek():
for indeks in range(0, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
def zapisz_plik():
with open(f"{tytul_tabeli}.csv", "a", newline = "") as plik:
csv.writer(plik).writerow(komorki)
tabela_gatunek = "ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek"
#dla odmian
for nr in range(1, 13):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
#i jeśli id odpowiada zmiennej tabela_gatunek
if tytul_tabeli == tabela_gatunek:
if path.isfile(f"{tabela_gatunek}.csv"):
komorki= [f"odmiana{nr}"]
for indeks in range(1, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
#zapisz listę tabeli do pliku o nazwie = id
zapisz_plik()
else:
komorki= [f"id_odmiany"]
#zapisz nagłówki tabeli
zapisz_naglowek()
#zapisz listę tabeli do pliku o nazwie = id
zapisz_plik()
komorki= [f"odmiana{nr}"]
#zapisz treść tabeli
for indeks in range(1, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
#zapisz listę tabeli do pliku o nazwie = id
zapisz_plik()
#jeśli strony nie ma, poinformuj
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
W linijkach 7-10 zapisujemy definicję funkcji. Teraz ta funkcja jest jako pierwsza, lubię, gdy zdefiniowane funkcje są zapisywane w logicznej kolejności i logiczne jest, że najpierw zapisujemy dane na liście a potem listę do pliku.
W 43 drugiej linijce wywołujemy funkcję. Usuń plik .csv i uruchom program. Zobacz czy działa poprawnie.
Idźmy za ciosem, skoro zapisujemy nagłówki, zapiszmy jeszcze treść. Zrobimy to osobną funkcją. Napisz ją i sprawdź czy działa. Moja wersja wygląda tak:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import csv
from os import path
def zapisz_naglowek():
for indeks in range(0, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
def zapisz_tresc():
for indeks in range(1, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
def zapisz_plik():
with open(f"{tytul_tabeli}.csv", "a", newline = "") as plik:
csv.writer(plik).writerow(komorki)
tabela_gatunek = "ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek"
#dla odmian
for nr in range(1, 13):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
#i jeśli id odpowiada zmiennej tabela_gatunek
if tytul_tabeli == tabela_gatunek:
if path.isfile(f"{tabela_gatunek}.csv"):
komorki= [f"odmiana{nr}"]
zapisz_tresc()
#zapisz listę tabeli do pliku o nazwie = id
zapisz_plik()
else:
komorki= [f"id_odmiany"]
#zapisz nagłówki tabeli
zapisz_naglowek()
#zapisz listę tabeli do pliku o nazwie = id
zapisz_plik()
komorki= [f"odmiana{nr}"]
#zapisz treść tabeli
zapisz_tresc()
zapisz_plik()
#jeśli strony nie ma, poinformuj
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
Już nie będę tłumaczył co się stało i gdzie, nie zrobiliśmy tym razem niczego nadzwyczajnego. Efekt jest taki, że mamy już 3 funkcje w naszym programie. Otwórz u siebie wersję bez funkcji i z funkcjami. U mnie wygląda to tak:
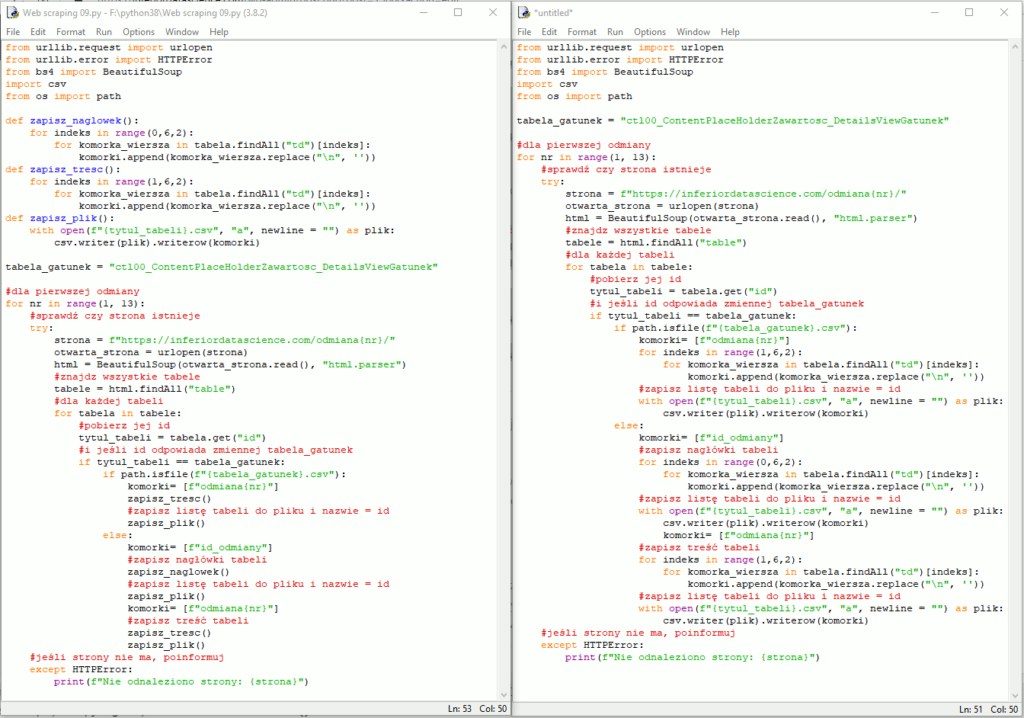
Widać na pewno większy porządek w wersji z funkcjami. Widać też, że wersja bez funkcji ma mniej linijek, ale gdy będziemy rozbudowywać program, ta rzecz ulegnie zmianie. Na ten moment mamy z głowy zapisywanie tabeli „gatunek”, przyjrzymy się tabeli „ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy”, którą w skrócie będziemy nazywać „statusy”. Tabela ma 3 nagłówki:
1. Status w krajowym rejestrze (KR)
2. Status w księdze ochrony (KO)
3. Zgoda na obrót
Wiemy już coś więcej o odmianach. Widać, że mogą być gdzieś zarejestrowane, być chronione i można, lub nie, nimi obracać. Kto by pomyślał, że tyle rzeczy się z odmianami dzieje.
Dodajmy do programu zapisywanie drugiej tabeli. Zrobimy to na spokojnie krok po kroku. Popatrz, tabela „statusy” ma tyle samo nagłówków co tabela „gatunek” w programie musimy tylko wybrać inne id tabeli, reszta zostaje bez zmian. Wydrukuj nagłówki i treść dla pierwszej odmiany. Mój program, w wersji bez funkcji wygląda tak:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
tabela_statusy = "ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy"
#dla pierwszej odmiany
for nr in range(1, 2):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
#i jeśli id odpowiada zmiennej tabela_statusy
if tytul_tabeli == tabela_statusy:
komorki= ["id"]
for indeks in range(0, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("to są nagłówki: ")
print(komorki)
komorki= [f"odmiana{nr}"]
for indeks in range(1, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("to jest treść: ")
print(komorki)
#jeśli strony nie ma, poinformuj
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
W 5 linijce zmieniliśmy nazwę zmiennej i jej treść na odpowiadającą id tabeli „statusy”.
W 21 linijce zmieniliśmy warunek, jaki powoduje, że instrukcja jest spełniona i się wykona.
W linijkach 22-33 drukujemy nagłówki i treść. Dla porządku efekt poniżej:
to są nagłówki:
['id', 'Status w krajowym rejestrze (KR)', 'Status w księdze ochrony (KO)', 'Zgoda na obrót']
to jest treść:
['odmiana1', 'R – Odmiana wpisana', '\xa0', '\xa0']
>>> Chwilowo nie będziemy się przejmować „\xa0”. Zobaczymy jak będą wyglądać pliki .csv. Dla nas ważne jest teraz dołączyć zapis drugiej tabeli do treści programu. Mamy dwie „identyczne” tabele, identyczne pod względem układu – jeden wiersz nagłówka, jeden wiersz danych i trzy kolumny.
Operatory logiczne
Wróćmy na chwilę do instrukcji warunkowej if. Popatrz na taki przykład:
lista = [-5,-4,-3,-2,-1,1,2,3,4,5,]
for element in lista:
if element > 0 and element < 3:
print(f"{element} jest liczbą dodatnią mniejszą od 3")
else:
print(f"{element} jest liczbą ujemną, lub dodatnią mniejszą od 3")
W 1 linijce definiujemy zupełnie nienadzwyczajną listę cyfr.
W 3 linijce zaczynamy pętlę, która będzie wybierać po kolei każdy element listy.
W 4 linijce jest instrukcja warunkowa if, ale z dwoma warunkami połączonymi słowem kluczowym and. Całą 4 linijkę można odczytać tak: Jeśli element listy jest większy od zera i mniejszy od 3 to:
W kolejnych linijkach drukujemy odpowiednie informacje.
By obsłużyć w naszym programie drugą tabelę potrzebujemy czegoś podobnego. Nie możemy napisać, że tytuł tabeli == „statusy” i tytuł tabeli == „gatunek”. Zróbmy jeszcze jeden przykład:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
tabela_gatunek = "ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek"
tabela_statusy = "ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy"
#dla pierwszej odmiany
for nr in range(1, 2):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
#i jeśli id odpowiada zmiennej tabela_gatunek lub tabela_statusy
if tytul_tabeli == tabela_gatunek or tytul_tabeli == tabela_statusy:
print(f"{tytul_tabeli} tej tabeli szukam")
else:
print(f"{tytul_tabeli} ta tabela mi nie jest potrzebna")
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
Przyjrzyj się 22 linijce: if tytul_tabeli == tabela_gatunek or tytul_tabeli == tabela_statusy: tutaj zamiast and mamy or, czyli zamiast i mamy lub. Tłumacząc warunek na polski otrzymujemy taką treść: Jeśli tytuł tabeli równy jest zmiennej tabela_gatunek lub tytuł tabeli jest równy zmiennej tabela_statusy to:
Pozostałe linijki znasz już pewnie na pamięć. Zobaczmy efekt działania programu:
==================== RESTART: F:\python38\Web scraping 09.py ===================
None ta tabela mi nie jest potrzebna
ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek tej tabeli szukam
ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy tej tabeli szukam
ctl00_ContentPlaceHolderZawartosc_DetailsViewNazwy ta tabela mi nie jest potrzebna
ctl00_ContentPlaceHolderZawartosc_GridViewHodowcyKR ta tabela mi nie jest potrzebna
None ta tabela mi nie jest potrzebna
>>> No i super. Wygląda na to, że drobna zmiana w naszym głównym programie pozwoli na skuteczne zapisywanie danych z dwóch tabel. Wprowadź zmianę, usuń pliki .csv i sprawdź czy program działa poprawnie. Mój wygląda tak:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import csv
from os import path
def zapisz_naglowek():
for indeks in range(0, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
def zapisz_tresc():
for indeks in range(1, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
def zapisz_plik():
with open(f"{tytul_tabeli}.csv", "a", newline = "") as plik:
csv.writer(plik).writerow(komorki)
tabela_gatunek = "ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek"
tabela_statusy = "ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy"
#dla odmian
for nr in range(1, 13):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
#i jeśli id odpowiada zmiennej tabela_gatunek lub tabela_statusy
if tytul_tabeli == tabela_gatunek or tytul_tabeli == tabela_statusy:
if path.isfile(f"{tytul_tabeli}.csv"):
komorki= [f"odmiana{nr}"]
zapisz_tresc()
#zapisz listę tabeli do pliku o nazwie = id
zapisz_plik()
else:
komorki= [f"id_odmiany"]
#zapisz nagłówki tabeli
zapisz_naglowek()
#zapisz listę tabeli do pliku o nazwie = id
zapisz_plik()
komorki= [f"odmiana{nr}"]
#zapisz treść tabeli
zapisz_tresc()
zapisz_plik()
#jeśli strony nie ma, poinformuj
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
W 36 linijce jest poprawiona instrukcja warunkowa if, która teraz jest prawdziwa dla dwóch różnych id.
W 37 linijce poprawiłem jeszcze wyszukiwanie, czy plik istnieje. Zamiast tabela_gatunek program wyszukuje dowolnej nazwy pliku, jaka aktualnie jest przypisana do zmiennej tytul_tabeli. Sprawdź, czy pliki zapisały się poprawnie. Wszystko jest ok? Nie trzeba było się nawet zajmować tajemniczym '\xa0′. Dwie tabele z głowy, lećmy do trzeciej.
Następna w kolejności będzie tabela z id ctl00_ContentPlaceHolderZawartosc_DetailsViewNazwy, w skrócie będziemy ją nazywać „nazwy”. Pewnie się domyślasz, że tym razem nie uda się zapisać tabeli w identyczny sposób, co poprzednie dwie, tutaj kolumn jest aż 7:
1. ostateczna
2. hodowlana
3. w badaniach
4. Status nazwy
5. Data zgł. nazwy
6. Data opubl. nazwy
7. Data zatw. nazwy
I znów wiemy coś więcej o odmianach. Jak widać, zanim odmiana dostanie chwytliwą nazwę w stylu Aramillo, występuje pod innymi nazwami. Pewnie ma to sens, po co wymyślać niesamowite nazwy dla odmian, które nie wiadomo, czy przejdą proces hodowli i badań. Widzimy też, że data zgłoszenia, zatwierdzenia i opublikowania nazwy jest istotna. Może producenci odmian mają skłonność do podkradania fajnych nazw?
Oczywiście nic nas nie powstrzyma od sprawdzenia co się wydarzy przy użyciu tych samych zakresów indeksów. Popatrz na taki program:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
tabela_nazwy = "ctl00_ContentPlaceHolderZawartosc_DetailsViewNazwy"
#dla 1 odmiany
for nr in range(1, 2):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
#jeśli tabela zawiera nazwy
if tytul_tabeli == tabela_nazwy:
komorki = ["id_odmiany"]
for indeks in range(0, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("nagłówek:")
print(komorki)
komorki= [f"odmiana{nr}"]
for indeks in range(1, 6, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("to jest treść: ")
print(komorki)
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
To prawie dokładna kopia programu, który już wykorzystywaliśmy w tym rozdziale, zmieniła się tylko tabela, teraz jest to tabela „nazwy”. Popatrzmy na efekt:
==================== RESTART: F:\python38\Web scraping 09.py ===================
nagłówek:
['id_odmiany', '– ostateczna', '– hodowlana', '– w badaniach']
to jest treść:
['odmiana1', 'Aramillo', 'LEKG 1215', 'LEKG 1215']
>>> Tak jak można było się spodziewać, program dodał tylko 3 nagłówki i 3 wartości pobrane z tabeli. Oczywiście bardzo łatwo możemy poprawić program:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
tabela_nazwy = "ctl00_ContentPlaceHolderZawartosc_DetailsViewNazwy"
#dla 1 odmiany
for nr in range(1, 2):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
#jeśli tabela zawiera nazwy
if tytul_tabeli == tabela_nazwy:
komorki = ["id_odmiany"]
for indeks in range(0, 14, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("nagłówek:")
print(komorki)
komorki= [f"odmiana{nr}"]
for indeks in range(1, 14, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("to jest treść: ")
print(komorki)
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
Zmieniliśmy w 2 miejscach zakres instrukcji iteracyjnej for, teraz jest to range(0, 14, 2) i range(1, 14, 2). Zobaczmy efekt:
==================== RESTART: F:\python38\Web scraping 09.py ===================
nagłówek:
['id_odmiany', '– ostateczna', '– hodowlana', '– w badaniach', 'Status nazwy', 'Data zgł. nazwy', 'Data opubl. nazwy', 'Data zatw. nazwy']
to jest treść:
['odmiana1', 'Aramillo', 'LEKG 1215', 'LEKG 1215', 'Z – Zatwierdzona', '05.06.2006', '15.07.2006', '22.02.2007']
>>> No i wszystko dobrze, ale do zapisu tej tabeli musimy dodać osobną funkcję, a może… nie? To jakie wartości wpisujemy w range() zależy wyłącznie od długości tabeli, prawda? Sprawdźmy czy mam rację, zobaczmy najpierw jak długie są poszczególne tabele:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
tabela_gatunek = "ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek"
tabela_statusy = "ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy"
tabela_nazwy = "ctl00_ContentPlaceHolderZawartosc_DetailsViewNazwy"
#dla 1 odmiany
for nr in range(1, 2):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
if tytul_tabeli == tabela_gatunek:
liczba_komorek = tabela.findAll("td")
print(len(liczba_komorek))
if tytul_tabeli == tabela_statusy:
liczba_komorek = tabela.findAll("td")
print(len(liczba_komorek))
if tytul_tabeli == tabela_nazwy:
liczba_komorek = tabela.findAll("td")
print(len(liczba_komorek))
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
W linijkach 23-24, 26-27, 29-30 sprawdzamy długość poszczególnych tabel. Znając ją, możemy podać odpowiedni argument funkcji range(). Zobaczmy co nasz program wypisał:
==================== RESTART: F:\python38\Web scraping 09.py ===================
6
6
14
>>> To teraz zaprzęgnijmy wiedzę o liczbie komórek w tabeli, do wypisania nagłówków i treści. Kod, który napisałem, będzie tylko chwilowo nieco długi i skomplikowany, chcę żebyś widział dokładnie co się dzieje krok po kroku:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
tabela_gatunek = "ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek"
tabela_statusy = "ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy"
tabela_nazwy = "ctl00_ContentPlaceHolderZawartosc_DetailsViewNazwy"
#dla 1 odmiany
for nr in range(1, 2):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
if tytul_tabeli == tabela_gatunek:
liczba_komorek = len(tabela.findAll("td"))
komorki = ["id_odmiany"]
for indeks in range(0, liczba_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("nagłówek:")
print(komorki)
komorki= [f"odmiana{nr}"]
for indeks in range(1, liczba_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("treść:")
print(komorki)
if tytul_tabeli == tabela_statusy:
liczba_komorek = len(tabela.findAll("td"))
komorki = ["id_odmiany"]
for indeks in range(0, liczba_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("nagłówek:")
print(komorki)
komorki= [f"odmiana{nr}"]
for indeks in range(1, liczba_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("treść:")
print(komorki)
if tytul_tabeli == tabela_nazwy:
liczba_komorek = len(tabela.findAll("td"))
komorki = ["id_odmiany"]
for indeks in range(0, liczba_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("nagłówek:")
print(komorki)
komorki= [f"odmiana{nr}"]
for indeks in range(1, liczba_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("treść:")
print(komorki)
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
W linijkach 23-36, 38-51, 53-66 dla każdej tabeli z osobna sprawdzamy długość i zapisujemy ją pod zmienną liczba_komorek a następnie wykorzystujemy ją w pętli for w funkcji range(). Skróćmy teraz program dodając or do instrukcji warunkowej if:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
tabela_gatunek = "ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek"
tabela_statusy = "ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy"
tabela_nazwy = "ctl00_ContentPlaceHolderZawartosc_DetailsViewNazwy"
#dla 1 odmiany
for nr in range(1, 2):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
if tytul_tabeli == tabela_gatunek or \
tytul_tabeli == tabela_statusy or \
tytul_tabeli == tabela_nazwy:
liczba_komorek = len(tabela.findAll("td"))
komorki = ["id_odmiany"]
for indeks in range(0, liczba_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("nagłówek:")
print(komorki)
komorki= [f"odmiana{nr}"]
for indeks in range(1, liczba_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
print("treść:")
print(komorki)
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
Teraz program wygląda przejrzyściej, prawda? A gdybyśmy dodali do programu jeszcze nasze dwie funkcje? Tą zapisującą nagłówki i tą zapisującą treść? Tym razem nasze funkcje będą potrzebować argumentu, w zależności od liczby komórek tabeli funkcja będzie działać nieco inaczej, przetestowaliśmy to, prawda? Pomyśl chwilę jak według Ciebie powinny te funkcje wyglądać, popatrz co wymyśliłem ja:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def zapisz_naglowek(ile_komorek):
for indeks in range(0, ile_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
def zapisz_tresc(ile_komorek):
for indeks in range(1, ile_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
tabela_gatunek = "ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek"
tabela_statusy = "ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy"
tabela_nazwy = "ctl00_ContentPlaceHolderZawartosc_DetailsViewNazwy"
#dla 1 odmiany
for nr in range(1, 2):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
if tytul_tabeli == tabela_gatunek or \
tytul_tabeli == tabela_statusy or \
tytul_tabeli == tabela_nazwy:
liczba_komorek = len(tabela.findAll("td"))
komorki = ["id_odmiany"]
zapisz_naglowek(liczba_komorek)
print("nagłówek:")
print(komorki)
komorki= [f"odmiana{nr}"]
zapisz_tresc(liczba_komorek)
print("treść:")
print(komorki)
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
Teraz nasza funkcja zapisz_naglowek(ile_komorek) potrzebuje jednego argumentu, argumentu mówiącego ile w sumie jest komórek w tabeli.
W 36 linijce wywołujemy funkcje z argumentem, którym jest zmienna liczba_komorek, której wartość zmienia się w zależności od tabeli. Zauważ, że w definicji funkcji używam innej nazwy na argument niż używana jest w programie (ile_komorek, liczba_komorek), nie chcemy wprowadzać zamętu i używać tych samych nazw w różnych miejscach.
Podobnie robimy z z funkcją zapisz_tresc(ile_komorek).
No to co? Popatrzymy jaki jest wynik działania nowych funkcji?
==================== RESTART: F:\python38\Web scraping 09.py ===================
nagłówek:
['id_odmiany', 'Gatunek', '– nazwa angielska', '– nazwa botaniczna']
treść:
['odmiana1', 'Kukurydza', 'Maize', 'Zea mays L.']
nagłówek:
['id_odmiany', 'Status w krajowym rejestrze (KR)', 'Status w księdze ochrony (KO)', 'Zgoda na obrót']
treść:
['odmiana1', 'R – Odmiana wpisana', '\xa0', '\xa0']
nagłówek:
['id_odmiany', '– ostateczna', '– hodowlana', '– w badaniach', 'Status nazwy', 'Data zgł. nazwy', 'Data opubl. nazwy', 'Data zatw. nazwy']
treść:
['odmiana1', 'Aramillo', 'LEKG 1215', 'LEKG 1215', 'Z – Zatwierdzona', '05.06.2006', '15.07.2006', '22.02.2007']
>>> Fantastycznie, ale możemy fantastyczność przenieść na jeszcze wyższy poziom. Trochę brzydko wygląda instrukcja warunkowa if z tymi trzema sprawdzaniami, są do siebie bardzo podobne, a już wiemy, że podobne rzeczy nie powinny być zapisywane w programie. Zrobimy znów prosty przykład:
lista = ["gatunek", "nazwy", "statusy"]
slowo = "nazwy"
if slowo in lista:
print(f"{slowo} jest na liście")
W 1 linijce definiujemy listę
W 2 linijce pod zmienną slowo podstawiamy jeden ze stringow obecnych na liście.
W 3 linijce nie sprawdzamy po kolei każdego ze słów z listy a po prostu wydajemy polecenie, które można przeczytać tak: jeśli wartość zmiennej slowo jest na liście nazwanej lista to:
W 4 linijce drukujemy komunikat potwierdzający, że słowo jest na liście. Zobaczmy działanie:
==================== RESTART: F:\python38\Web scraping 09.py ===================
nazwy jest na liście
>>> Upewnijmy się, czy program działa dobrze działa, zmienimy go nieco:
lista = ["gatunek", "nazwy", "statusy"]
slowo = "kury"
if slowo in lista:
print(f"{slowo} jest na liście")
W 2 linijce mamy inne słowo, nie ma go na liście. Efekt działania:
==================== RESTART: F:\python38\Web scraping 09.py ===================
>>> Nic się nie wypisało, warunek nie został spełniony, wszystko działa jak powinno.
Wprowadźmy tę ostatnią poprawkę:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def zapisz_naglowek(ile_komorek):
for indeks in range(0, ile_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
def zapisz_tresc(ile_komorek):
for indeks in range(1, ile_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
id_tabel = ["ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek",
"ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy",
"ctl00_ContentPlaceHolderZawartosc_DetailsViewNazwy"]
#dla 1 odmiany
for nr in range(1, 2):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
if tytul_tabeli in id_tabel:
liczba_komorek = len(tabela.findAll("td"))
komorki = ["id_odmiany"]
zapisz_naglowek(liczba_komorek)
print("nagłówek:")
print(komorki)
komorki= [f"odmiana{nr}"]
zapisz_tresc(liczba_komorek)
print("treść:")
print(komorki)
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
W linijkach 13-15 definiujemy listę z id tabel. Przy wypisywaniu elementów listy, po każdym przecinku możesz wcisnąć enter, bez strachu, że Python się pogubi w wielu linijkach, listy są przyjazne w tym względzie.
W 30 linijce stosujemy ładniejszą instrukcję warunkową if, która sprawdza, czy szukane id tabeli jest na zdefiniowanej liście. Zobaczmy efekt:
==================== RESTART: F:\python38\Web scraping 09.py ===================
nagłówek:
['id_odmiany', 'Gatunek', '– nazwa angielska', '– nazwa botaniczna']
treść:
['odmiana1', 'Kukurydza', 'Maize', 'Zea mays L.']
nagłówek:
['id_odmiany', 'Status w krajowym rejestrze (KR)', 'Status w księdze ochrony (KO)', 'Zgoda na obrót']
treść:
['odmiana1', 'R – Odmiana wpisana', '\xa0', '\xa0']
nagłówek:
['id_odmiany', '– ostateczna', '– hodowlana', '– w badaniach', 'Status nazwy', 'Data zgł. nazwy', 'Data opubl. nazwy', 'Data zatw. nazwy']
treść:
['odmiana1', 'Aramillo', 'LEKG 1215', 'LEKG 1215', 'Z – Zatwierdzona', '05.06.2006', '15.07.2006', '22.02.2007']
>>> No, z takiego kodu i efektu jego działania możemy być zadowoleni! Teraz poprawione funkcje i listę id tabel wrzucimy do naszego głównego programu, to tylko kilka kliknięć:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import csv
from os import path
def zapisz_naglowek(ile_komorek):
for indeks in range(0, ile_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
def zapisz_tresc(ile_komorek):
for indeks in range(1, ile_komorek, 2):
for komorka_wiersza in tabela.findAll("td")[indeks]:
komorki.append(komorka_wiersza.replace("\n", ''))
def zapisz_plik():
with open(f"{tytul_tabeli}.csv", "a", newline = "") as plik:
csv.writer(plik).writerow(komorki)
id_tabel = ["ctl00_ContentPlaceHolderZawartosc_DetailsViewGatunek",
"ctl00_ContentPlaceHolderZawartosc_DetailsViewStatusy",
"ctl00_ContentPlaceHolderZawartosc_DetailsViewNazwy"]
#dla odmian
for nr in range(1, 13):
#sprawdź czy strona istnieje
try:
strona = f"https://inferiordatascience.com/odmiana{nr}/"
otwarta_strona = urlopen(strona)
html = BeautifulSoup(otwarta_strona.read(), "html.parser")
#znajdz wszystkie tabele
tabele = html.findAll("table")
#dla każdej tabeli
for tabela in tabele:
#pobierz jej id
tytul_tabeli = tabela.get("id")
##i jeśli id znajduje się na liście id_tabel
if tytul_tabeli in id_tabel:
if path.isfile(f"{tytul_tabeli}.csv"):
komorki= [f"odmiana{nr}"]
zapisz_tresc(len(tabela.findAll("td")))
#zapisz listę tabeli do pliku o nazwie = id
zapisz_plik()
else:
komorki= [f"id_odmiany"]
#zapisz nagłówki tabeli
zapisz_naglowek(len(tabela.findAll("td")))
#zapisz listę tabeli do pliku o nazwie = id
zapisz_plik()
komorki= [f"odmiana{nr}"]
#zapisz treść tabeli
zapisz_tresc(len(tabela.findAll("td")))
zapisz_plik()
#jeśli strony nie ma, poinformuj
except HTTPError:
print(f"Nie odnaleziono strony: {strona}")
Co my tu mamy, ano:
W linijkach 7-14 są nasze przedefiniowane funkcje, wyposażone w argument.
W linijkach 19-21 pojawia się lista id tabel.
W 37 linijce używamy naszej ładniejszej wersji instrukcji warunkowej if, korzystającej z listy id tabel.
W linijkach 40, 46 i 51 wywołujemy nasze funkcje, zdecydowałem się nie podstawiać liczby komórek pod żadną zmienną, a użyć jej bezpośrednio jako argumentu funkcji.
Sprawdź czy program działa i ciesz się sukcesem! W tej części nauczyłeś się naprawdę sporo! Zaczynając od podstawowych operacji na plikach, poprzez funkcje z argumentami i bez, kończąc na zaawansowanych warunkach w instrukcji if.
Zadanie Domowe
Podążanie za instrukcjami, nawet jeśli je wszystkie wykonujesz samodzielnie, nie zrobi z ciebie programisty. Zadania domowe mogą wydawać się na początku trudne. Tu nie ma rozwiązania podanego na talerzu, użyj dowolnych źródeł, by znaleźć odpowiedź.
- Przygotuj listę z następującymi wartościami -3, -2, -1, 0, 1, 2, 3. Napisz jedną instrukcję warunkową if, która spełni warunek, że element listy równa się 0. Nie możesz użyć if zmienna == 0. Wszystkie inne ciosy dozwolone 😉
- Zdefiniuj funkcję, której argumentem jest lista. Niech funkcja sprawdza dla każdego elementu listy czy element jest tekstem (string), czy liczbą całkowitą (int). Przetestuj działanie na dowolnej liście.